
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- mutex
- 스레드
- 세마포어
- local cache
- BOJ
- 가상 메모리
- 스케줄링
- 교착상태
- 기아 상태
- 페이징
- 프로세스
- garbage collection
- 운영체제
- 단편화
- redis
- 인터럽트
- Algorithm
- 페이지 부재율
- ALU
- 부동소수점
- 백준
- 알고리즘
- 우선순위
- fork()
- PYTHON
- gc
- mips
- 페이지 대치
- concurrency
- 컴퓨터구조
- Today
- Total
봉황대 in CS
[Server] 왜 Redis cache 사용 시 GC가 자주 발생할까? 본문
Redis & Local cache를 통한 조회 성능 개선기에서 활성(active) 이벤트 조회 기능에 대하여 총 세 단계를 거침으로써 성능 개선을 이루었다.
0. DB에서 직접 조회 by. Table full scan (평균 TPS : 31.3)
1. DB에서 직접 조회 by. Index range scan (평균 TPS : 101.5)
2. Caching : Redis cache (평균 TPS : 9.8)
3. 2-level caching : Local cache + Redis cache (평균 TPS : 619.2)
이 글에서 중점으로 다룰 부분은 2번, Redis를 단일 Cache server로 둔 경우에 대해서이다. 부하 테스트를 하면서 시스템을 모니터링하는 중에 이 경우에서만 GC가 매우 높은 빈도로 발생하는 것을 발견하였다. 메모리 할당 그래프도 혼자 다른 양상을 가지고 있었다.

각 수치가 어떤 것을 뜻하며 왜 이런 현상이 발생하는지를 알기 위해 JVM의 메모리 할당과 GC에 대해서 학습을 진행하였고, (관련 포스팅 : JVM의 메모리 할당 전략과 Garbage Collection, G1 Garbage Collector의 기본 개념과 동작 과정) 학습한 내용을 바탕으로 분석한 결과를 이번 글에 남기고자 한다.
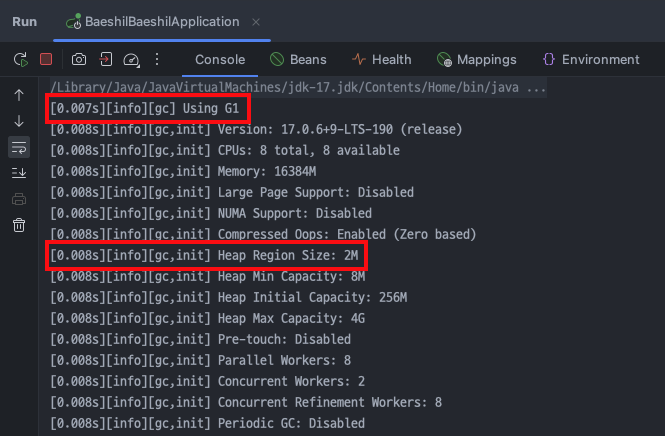
실행 환경
GC 관련해서는 따로 설정한 값이 없어서 모두 default 값을 따른다. G1 가비지 컬렉터가 사용되었고, 각 Region의 크기는 2 MB이다. 따라서 객체의 크기가 Region의 절반인 2 MB / 2 = 1 MB를 넘는다면 이는 Humongous object로 분류된다.
부하 테스트는 nGrinder를 통해 100개의 스레드가 각각 100개의 요청을 동시에 보내도록 하였다. 따라서 총 요청 횟수는 10,000번인데, 요청 처리 속도가 너무 느려서 테스트가 도저히 끝나질 않아 3분 32초까지만 돌렸다. 이에 실행된 요청은 1,883개이다.
Profiler를 통해 메모리 할당량 확인하기
어디서 메모리 할당이 많이 발생했을까? 나는 첫 번째로 Redis에서 이벤트 목록 데이터를 받아왔을 때 그리고 두 번째로 활성 상태인 데이터들만 필터링하여 새로운 ArrayList에 저장할 때가 원인이었을 것이라고 예상했다. 그러나 메모리 할당량을 직접 찍어보니, 나의 예상은 반절만 맞고 반절은 틀렸다. IntelliJ에서 제공하는 Profiler를 사용하면 각 메서드마다 메모리 할당이 얼마만큼 발생했는지(Profiling 동안 할당한 양의 총합)를 알 수 있다.
활성 이벤트 목록을 반환하는 getActiveEvents 메서드는 크게 세 부분으로 나뉜다.
1. loadFromCache : Redis 캐시 서버에서 이벤트 목록을 가져온다.
→ 총 436.03 GB 사용
2. loadEvents : Redis에 캐싱되어 있는 데이터가 없다면 DB에서 직접 조회해온다.
→ 총 14.55 GB 사용
3. filterEvents : 활성 상태인 이벤트를 필터링한다.
→ 총 9.67 MB 사용
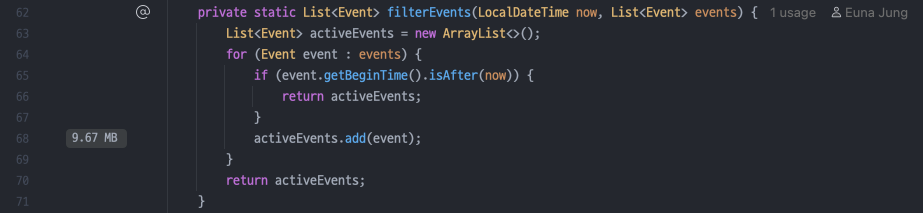
나의 예상과는 다르게, 필터링하는 부분에서는 할당이 크게 발생하지 않았다. 그 이유는 캐시에 올라간 이벤트 목록에 존재하는 이벤트의 개수는 22,832개인데, 활성 상태로 필터링된 이벤트들은 368개 밖에 되지 않았기 때문이다. (만약 필터링된 데이터의 개수도 컸다면 GC에 contribution이 좀 있을 수도 있겠다.)
자세히 까봐야 하는 부분은 loadFromCache 메서드, 즉 Redis에서 데이터를 가져오는 부분이다. 아래 profiling 결과를 보면 두 곳에서 할당이 크게 발생하였다. 첫 번째, Redis에서 데이터를 받아왔을 때이며 총 127.41 GB의 할당이 발생하였다. Redis와는 데이터를 String 형으로 주고받는다. GzipRedisSerializer를 통해 데이터에 대한 압축을 진행하고 난 다음에 캐시에 올렸음에도 불구하고 이벤트 목록 데이터의 크기가 워낙 커서 큰 할당이 발생한 것으로 보인다. 두 번째, String 형 데이터를 객체로 역직렬화할 때였다. GC가 자주 발생하게 된 것의 원인이 되는 부분으로, 총 323.01 GB의 할당이 발생하였다. 어찌 보면 정말 당연한 부분인데 .. 이 부분에 대해선 전혀 예상하지 못했다. 정리하자면, Redis에서 가져온 하나의 데이터에 대해서 총 2번의 할당이 발생한 것이고, 이 데이터가 거대한 크기를 가졌기 때문에 그 파급 효과가 크게 나타났던 것이다.
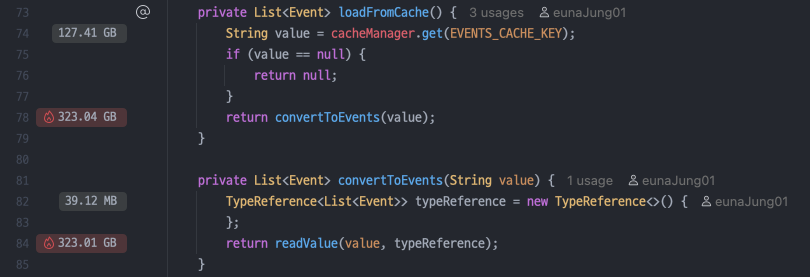
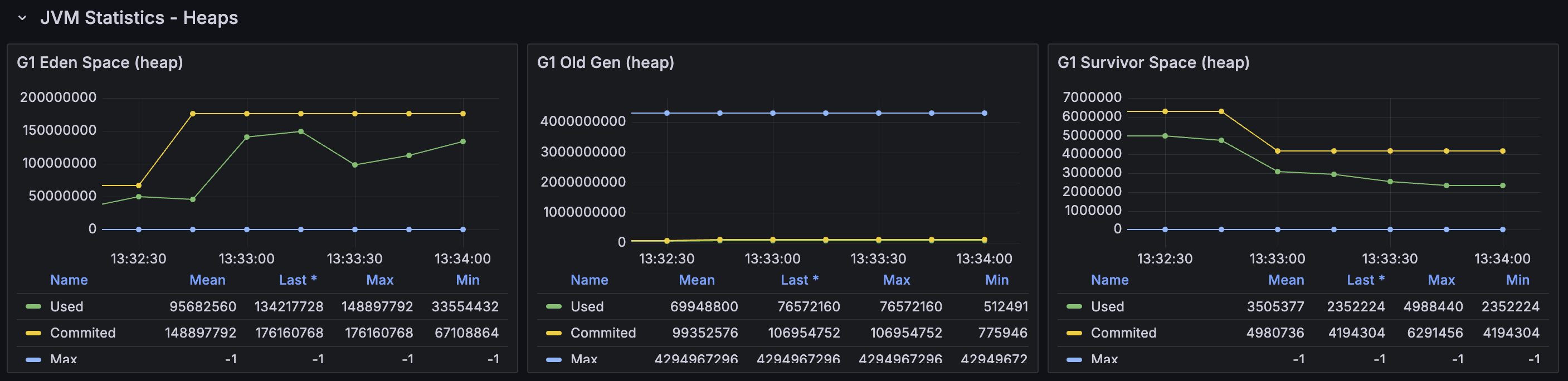
String 형 데이터를 객체로 변환하는 것에 총 323.04 GB가 할당되었고 총 1,883개의 요청이 실행되었으니, naive 하게는 한 번 실행할 때마다 323.04 GB / 1,883 ≈ 175.27 MB가 할당되었다고 볼 수 있다. G1 컬렉터에서는 Region 크기의 50% 이상인 객체들은 Humongous object로 간주하고 이를 Humongous region에 할당한다. 즉, 곧바로 Old generation에 할당되는데, 방금 계산한 수치는 Region의 절반 이상을 훌쩍 넘기 때문에 항상 Humongous region에 할당되었을 것이다. Old generation에 대한 GC는 Young generation 보다는 드문 빈도로 발생하며 Humongous object는 한번 할당되면 더 이상 사용되지 않을 때까지 다른 메모리 공간으로 절대 움직이지 않는다. 따라서 Humongous region이 많아진다면 Memory fragmentation 문제가 심화되며, 할당 실패로 인한 Full GC가 발생하는 것을 피하기 위해서 Minor GC를 더 자주 호출할 수 있다. 이제 이 부분을 그래프에서 확인해 보자.
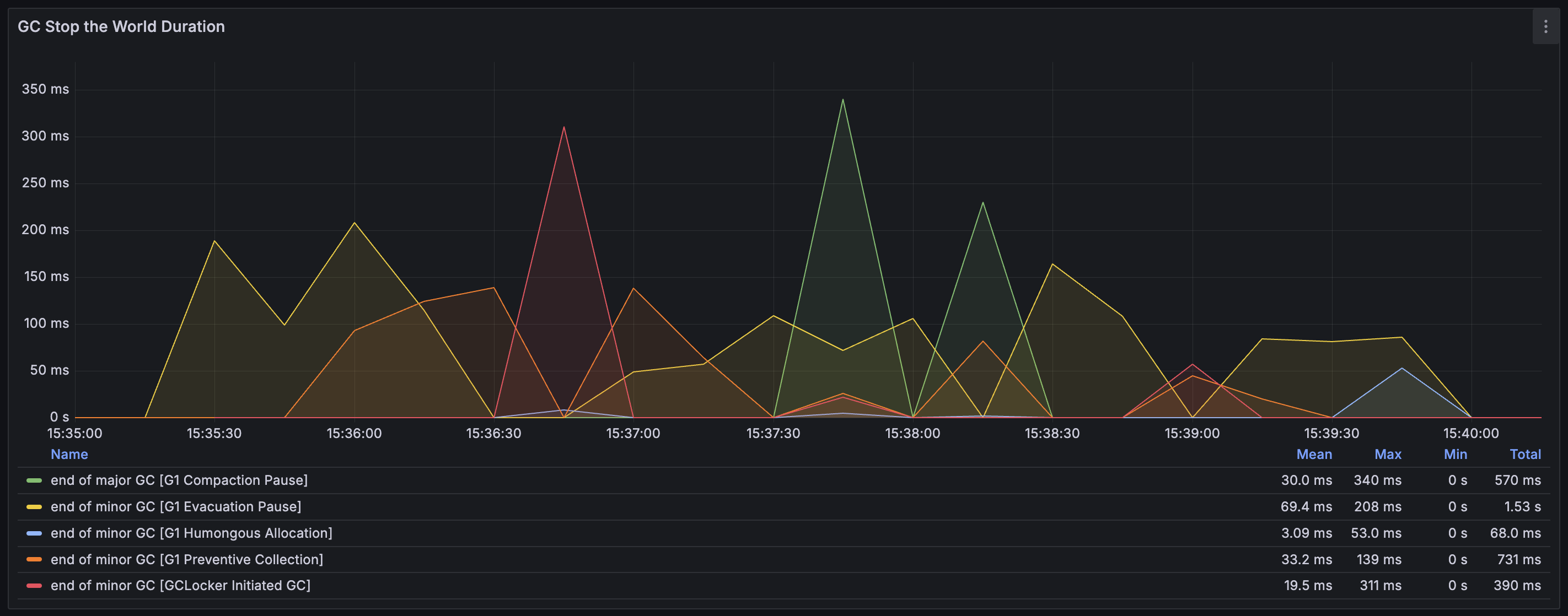
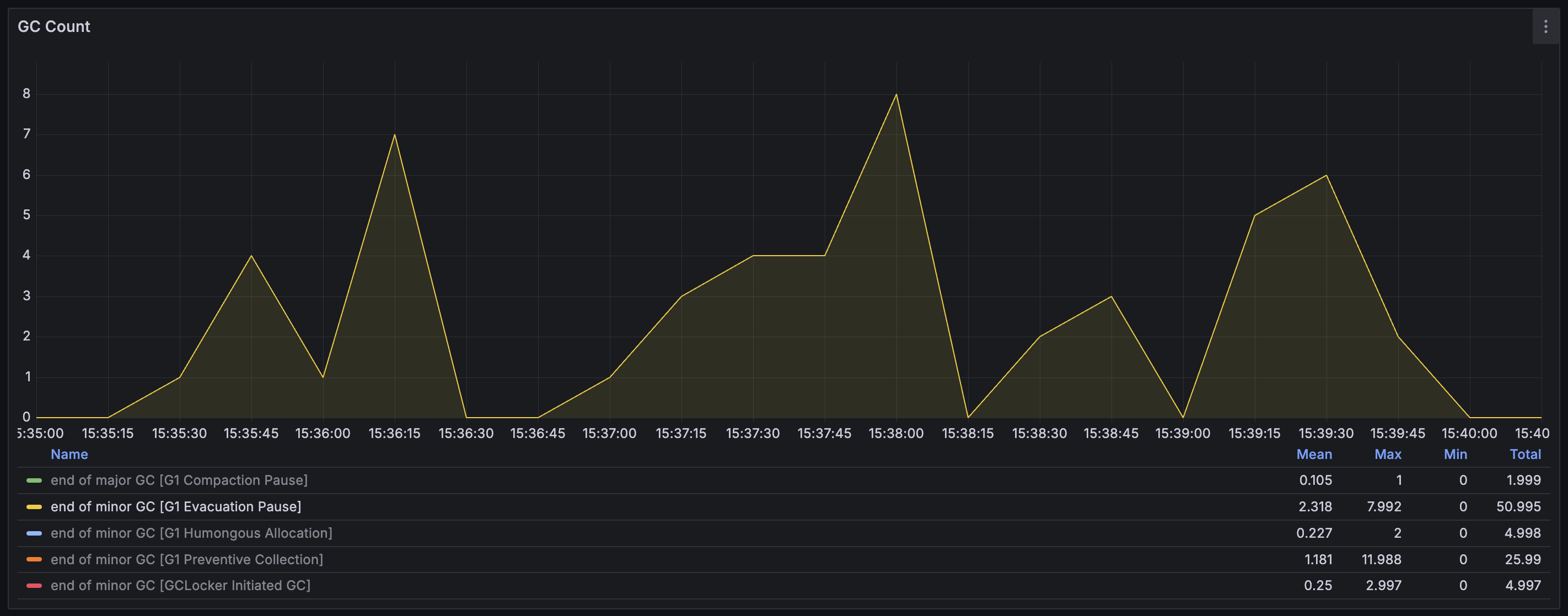
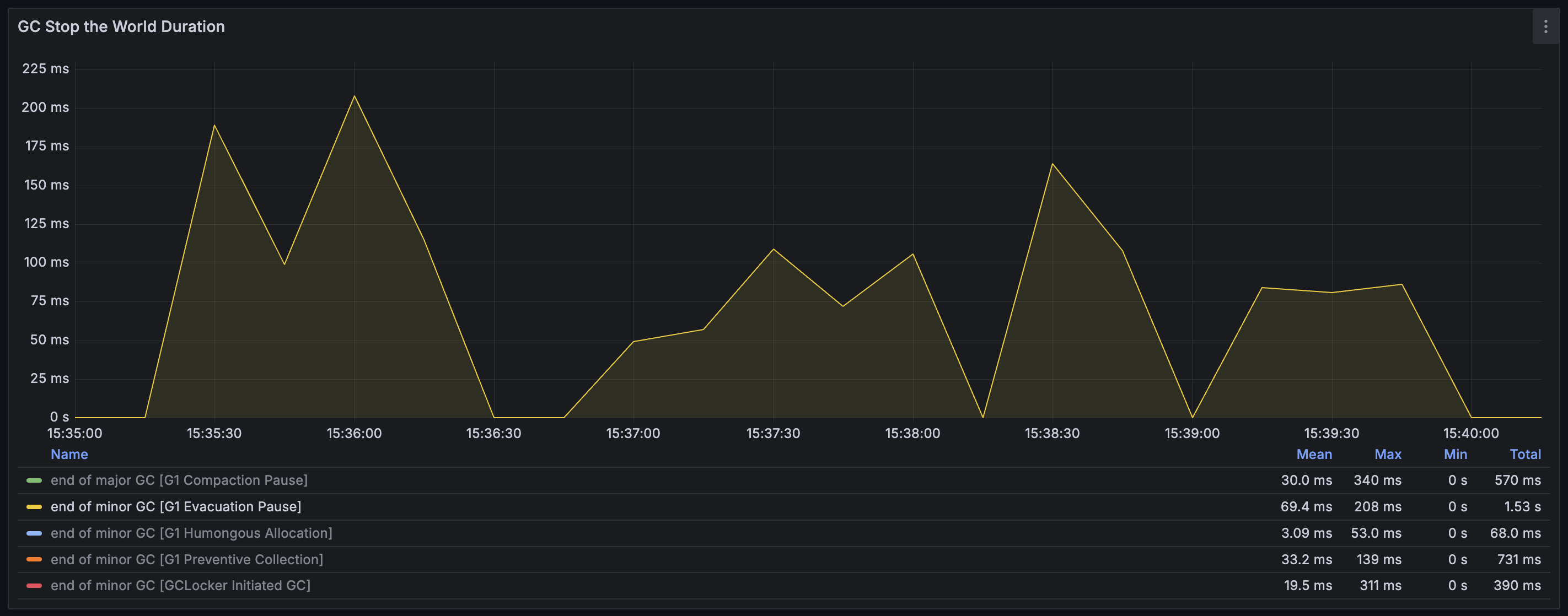
GC Count & Stop the World Duration 그래프 해석
'GC count'는 GC로 인한 pause가 초당 몇 번 발생했는지를 나타낸다. 그리고 'GC stop the world duration'은 GC pause가 몇 ms 발생하였는지를 나타낸다. 그래프에서는 GC pause들이 동시에 발생한 것처럼 보인다. 하지만 이는 Prometheus의 irate를 통해서 일정 간격 동안의 수치를 평균화해서 보여주는 것이기 때문에 그렇게 보이는 것일 뿐, GC 이벤트들은 순차적으로 발생한다.
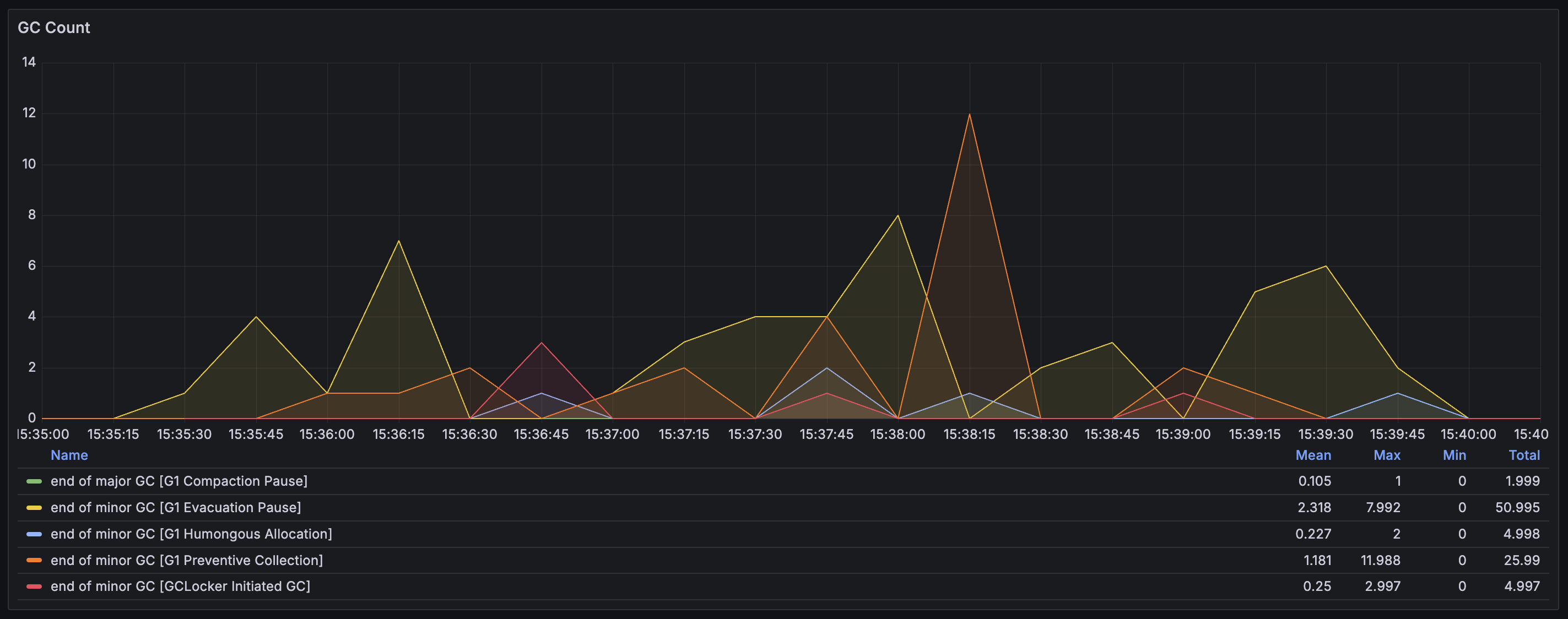
범례에 보이는 총 5가지 요소들이 각각 무엇을 뜻하는지 간단히 정리해 보면 ..
- end of major GC [G1 Compaction Pause]
: Full GC, Memory fragmentation이 극심해져 Heap 전체를 대상으로 압축(compaction)을 수행함 - end of minor GC [G1 Evacuation Pause]
: Young GC, Eden 영역이 가득 차서 Survivor 영역 또는 Old generation으로 이동시키기 위함 - end of minor GC [G1 Humongous Allocation]
: Young GC, 큰 객체를 할당할 연속된 공간을 찾지 못해서 수행함 - end of minor GC [G1 Preventive Collection]
: Young GC, Full GC가 발생하는 것을 방지하기 위함 - end of minor GC [GCLocker Initiated GC]
: Young GC, GCLocker 메커니즘 때문에 발생
여기서 GCLocker란, Java 외부 네이티브 코드(C/C++)가 JNI(Java Native Interface)를 통해 JVM에 접근하는 상황에서(e.g., 네이티브 코드에서 JVM 객체를 참조) GC와 충돌하지 않도록 아예 GC를 막아버리는 보호장치이다. 네이티브 코드가 끝났다면, 이 GCLocker로 인해 미뤄두었던 GC를 시작하게 된다. 내가 프로젝트에서 네이티브 코드를 직접 호출한 곳은 없었고, 사용한 라이브러리들 중에 JNI를 쓰는 자식이 있는 것 같다.
GCLocker initiated GC를 제외하고, 나머지 놈들을 자세히 봐보자.
G1 Compaction Pause
전체 Heap을 대상으로 진행한 Full GC가 발생하였음을 나타낸다. Full GC는 메모리가 고갈되었거나, Heap 전체에 대해서 Fragmentation이 심화되어 객체를 할당하기 위한 메모리 상에서 연속된 공간을 찾지 못하였고 Young GC 만으로는 해소가 불가능할 때 발생한다. 따라서 단편화를 해결하는 Compaction 과정이 발생하는데, 전체 Heap을 스캔하면서 도달 가능한 객체들을 한쪽으로 모으는 작업을 진행하여 연속된 메모리 영역을 확보하게 된다. (Mark and compact 알고리즘) Full GC는 매우 무거운 작업이기에 모든 pause 중에서 가장 높은 pause 시간인 340 ms을 기록하는 것 또한 볼 수 있다.
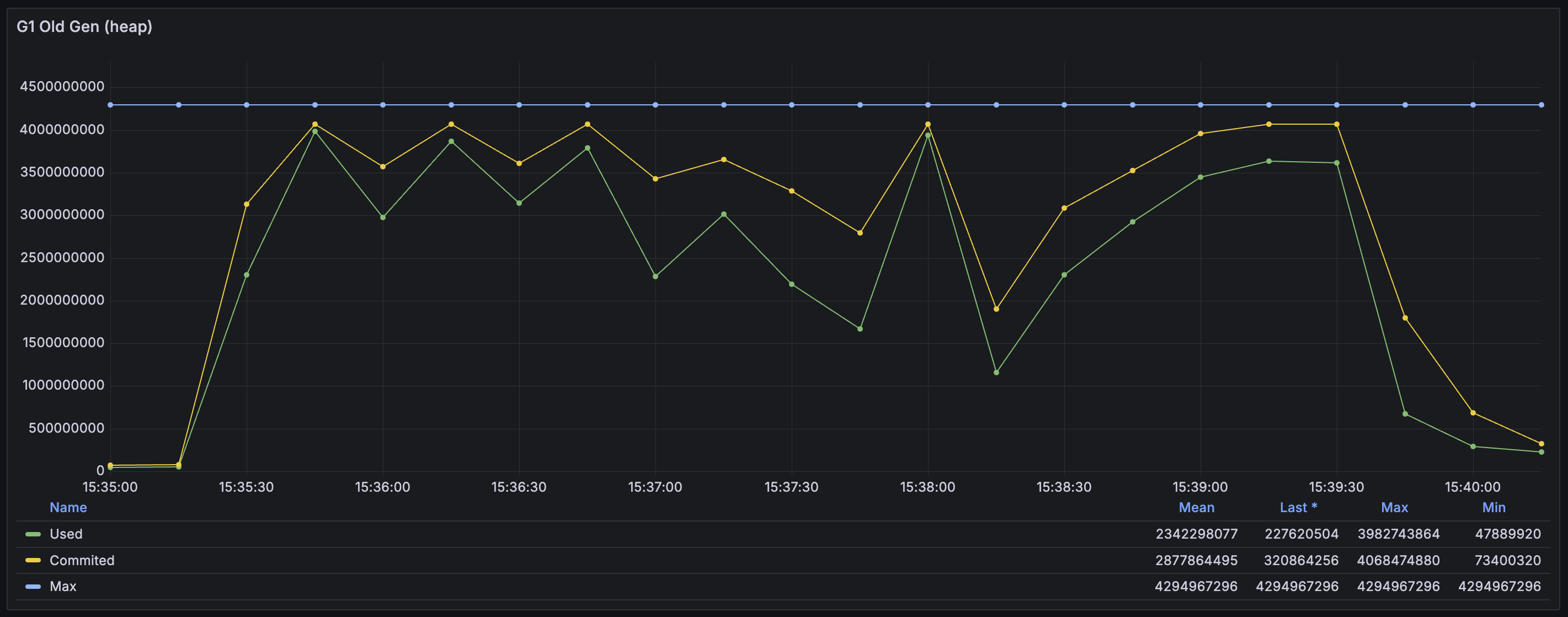
왜 이것이 발생했는지를 해석해 보자면, Redis에서 데이터를 가져오고 변환을 진행하면서 거대 객체들이 너무 많이 할당되었고 fragmentation도 극심해졌는데 이들을 메모리 상의 다른 위치로 옮길 수도 없어서 다른 거대 객체를 할당할 수 없는 상황까지 왔던 것 같다. (아래 Old generation 할당량 그래프 참고)
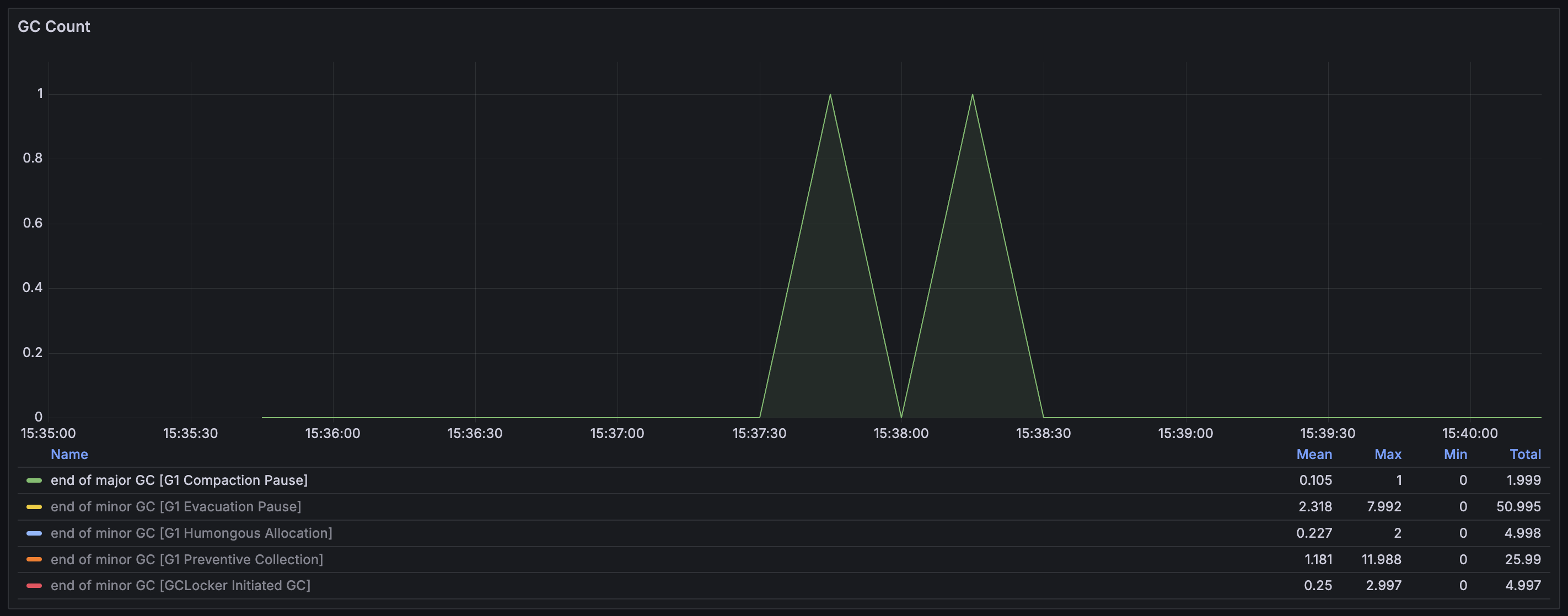
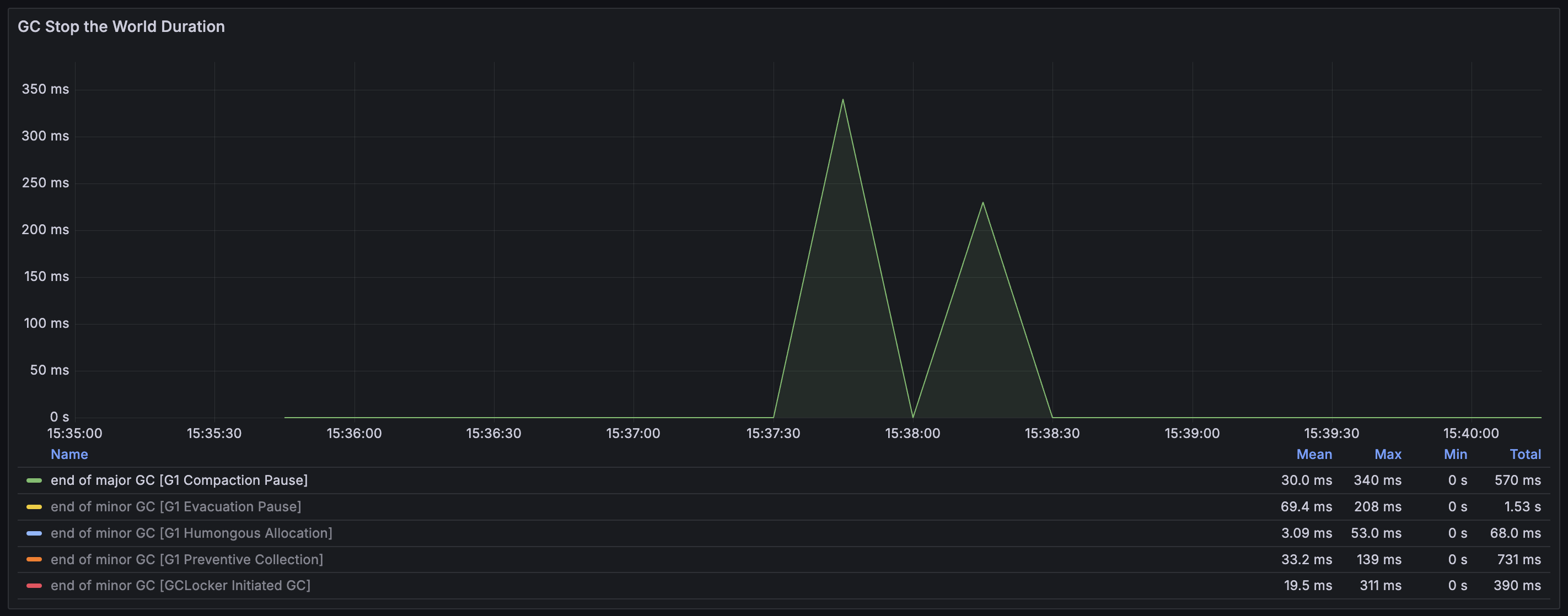
G1 Evacuation Pause
Young generation의 Eden 영역이 가득 찼을 때 발생하는 GC이다. Eden 영역은 객체가 처음 할당되면 위치하게 되는 곳이다. 이 GC는 프로그램 수행 중에 자연스럽게 발생하는 일반적인 GC로, 살아남은 객체들을 나이에 따라 Survivor 영역 또는 Old generation으로 승격시킨다. 문제는 총 발생 횟수가 50.985번으로 너무 자주 발생했다는 것이다. GC가 너무 자주 발생한다면 Application의 Response latency에 악영향을 끼치게 된다. (이후 설명할 내용이지만, DB에서 활성 이벤트 목록 데이터를 직접 조회해 오는 경우에는 전체 테스트 수행 기간 동안 이 GC가 5번만 발생하였고, Local cache를 사용하는 경우에는 단 한 번만 발생하였다.)
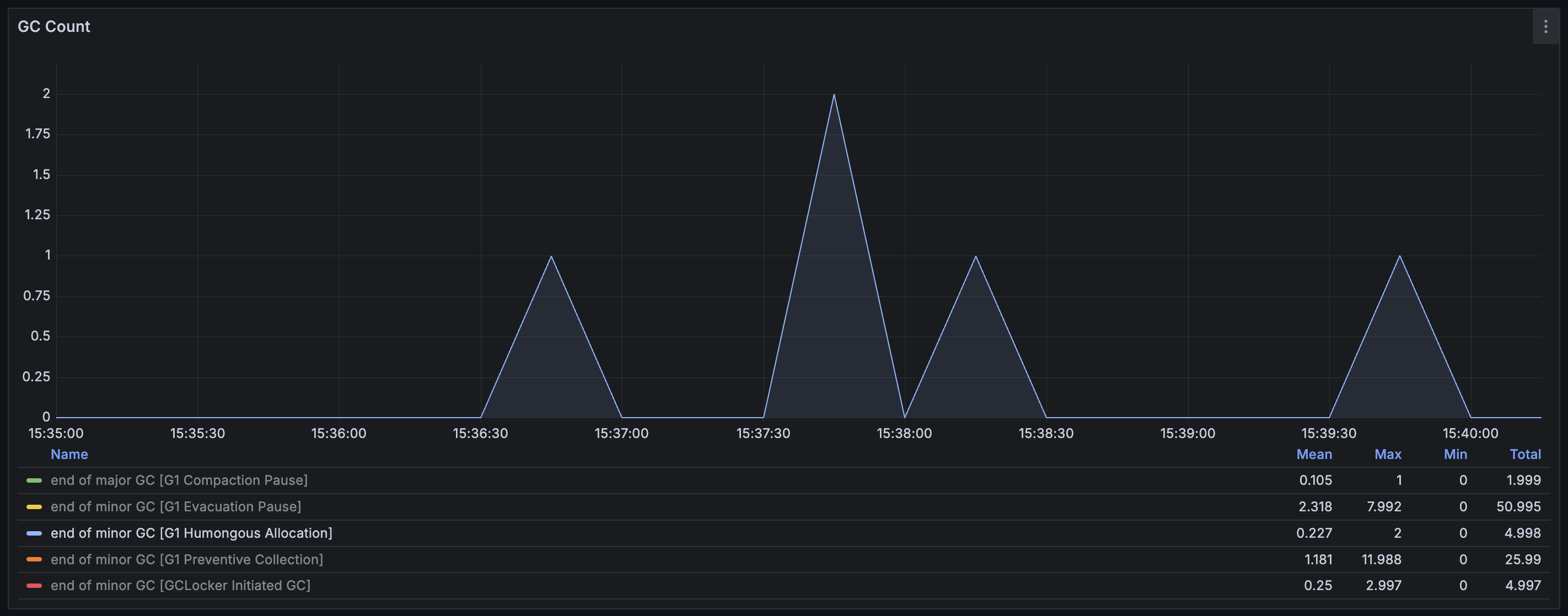
G1 Humongous Allocation
Humongous object을 할당하려고 할 때 연속된 공간을 찾지 못해서 발생하는 GC이다. Young GC를 통해서 fragmentation을 줄이는 것이 목적인데, 만약 이 과정을 통해서 충분한 공간을 확보하지 못했다면 Full GC로 이어진다. 15:37:30 ~ 15:38:30 시점에서 발생한 2번의 GC가 Full GC로 이어진 것으로 보인다. 이때 Heap 전체적으로 Memory fragmentation이 극심했던 것이고, Humongous object들이 너무 많이 존재했던 것으로 해석된다.
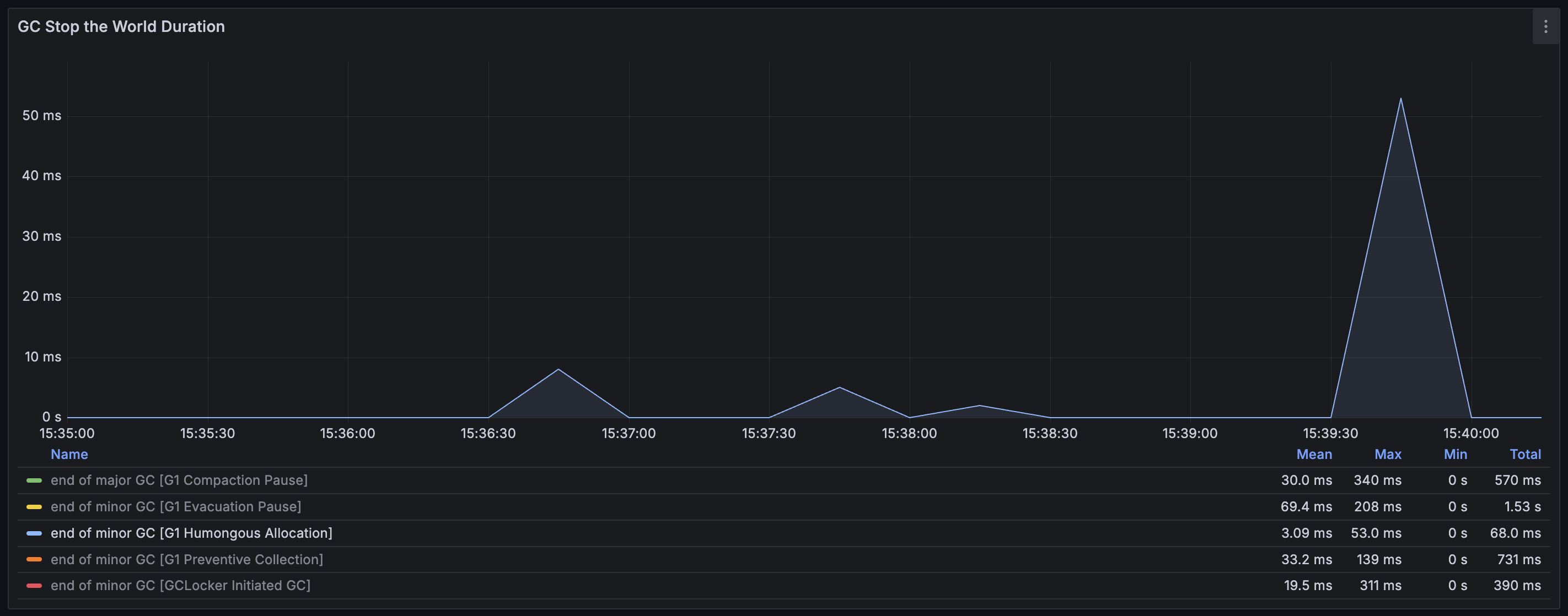
G1 Preventive Collection
Old generation이 곧 가득 찰 것으로 예상되어 Full GC가 발생하는 것을 방지하기 위해 실행된 Young GC이다. 총 발생 횟수가 25.99번으로 상당히 높은데, 그만큼 Old generation 영역의 max까지 자주 도달했다는 것이다.
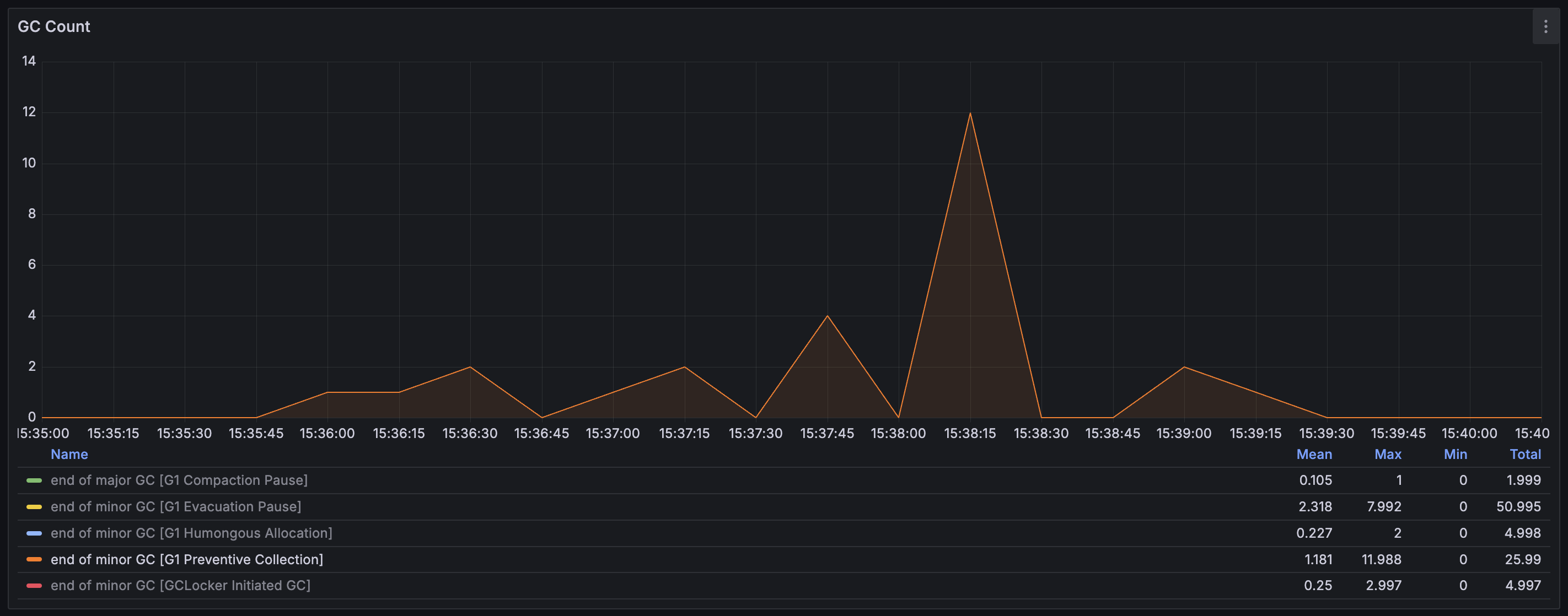
정리
여러 종류의 GC들을 심각한 순서대로 나열해 보면 다음과 같다.
1. G1 Compaction Pause : Full GC의 발생 == 최악의 상황
2. G1 Preventive Collection : Old generation의 부족 감지 → Full GC를 방지하기 위한 GC
3. G1 Humongous Allocation : 메모리 상 연속 공간을 확보하지 못했기 때문에 발생한 GC
4. G1 Evacuation Pause
이들이 발생한 원인은 Humongous object 대량 할당과 Memory fragmentation의 심화이며, 결국 Full GC를 피하지 못한 최악의 상황까지 간 것이다. -XX:G1HeapRegionSize option을 통해서 Humongous object로 판단되는 객체들을 줄여볼 수 있으나, 엄청나게 거대한 객체들을 계속 할당하는 지금 상황에서는 이런 튜닝 방식은 소용이 없을 것으로 보인다.
다른 경우에서의 메모리 할당 & GC 경향은 어떠한가?
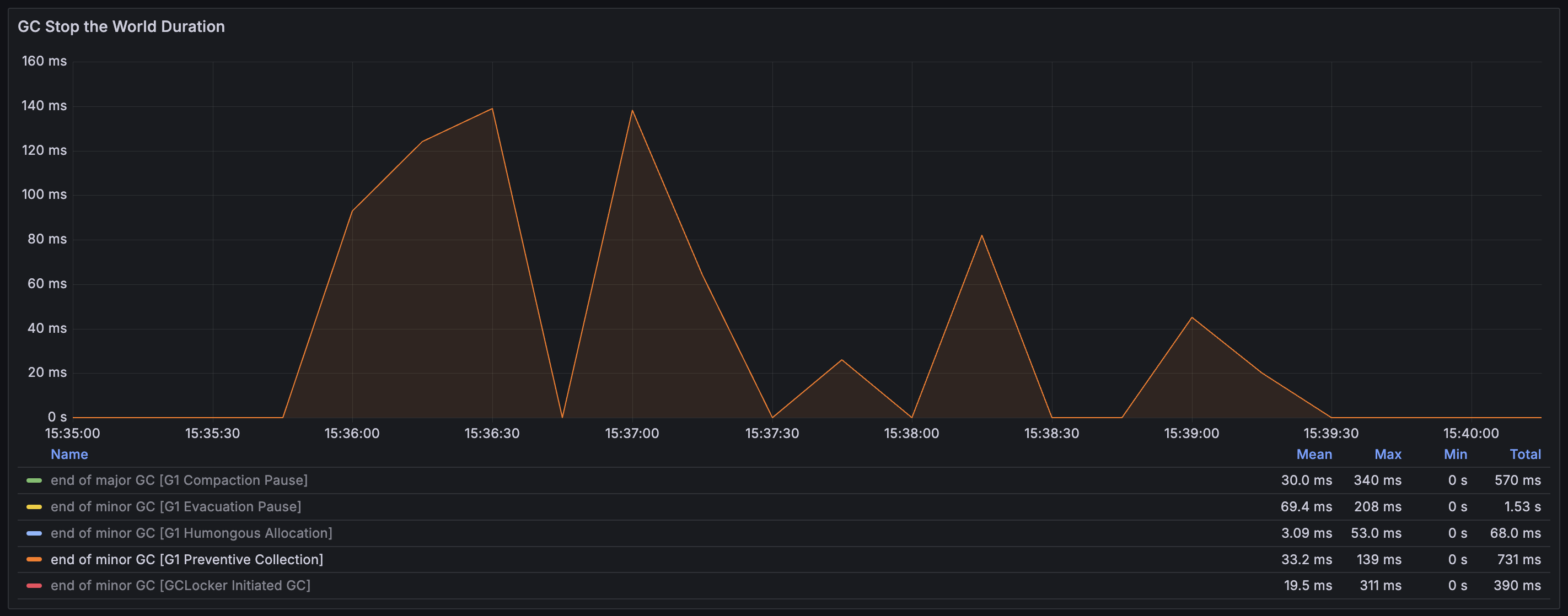
DB에서 직접 조회하는 경우
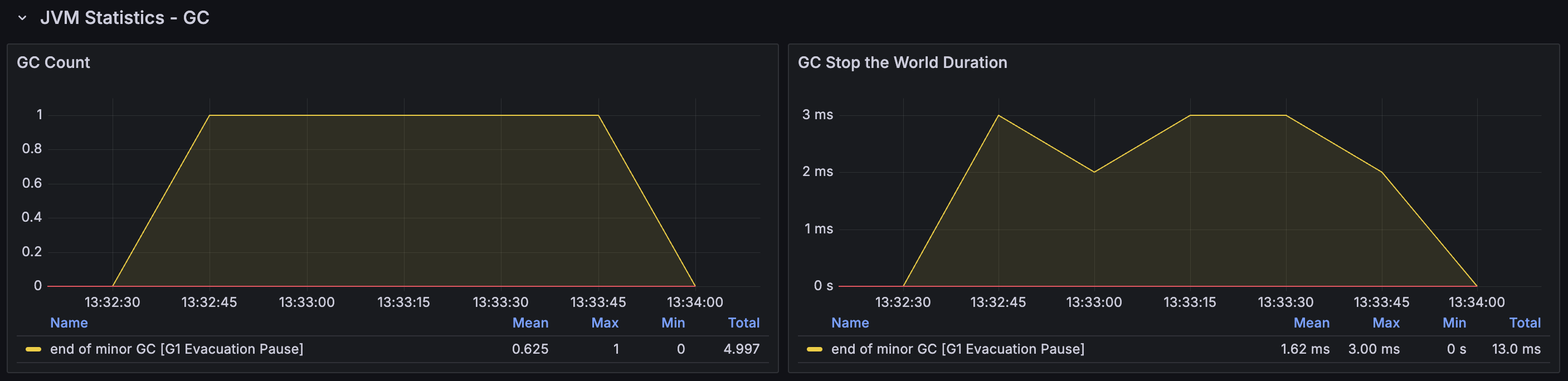
DB에서 직접 활성 이벤트 목록을 조회하여 가져왔을 때의 메모리 할당량은 전체 테스트 동안, 즉 총 10,000번의 요청동안 12.91 GB 밖에 되지 않는다. 따라서 일반적인 GC인 G1 Evacuation pause 만이 발생하며, 횟수도 약 5번만 발생한다.

2-level caching(Local cache + Redis cache)을 사용하는 경우
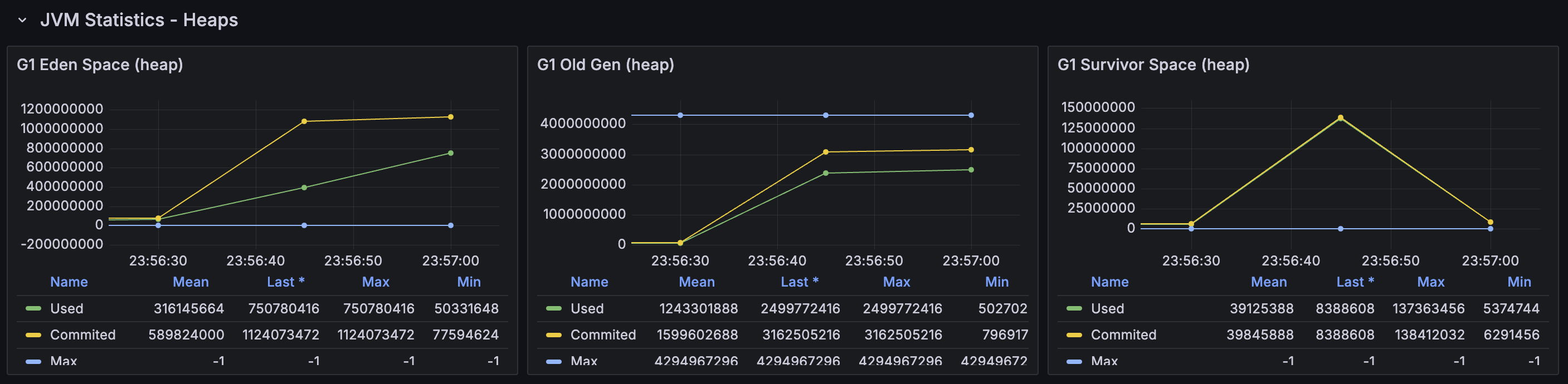
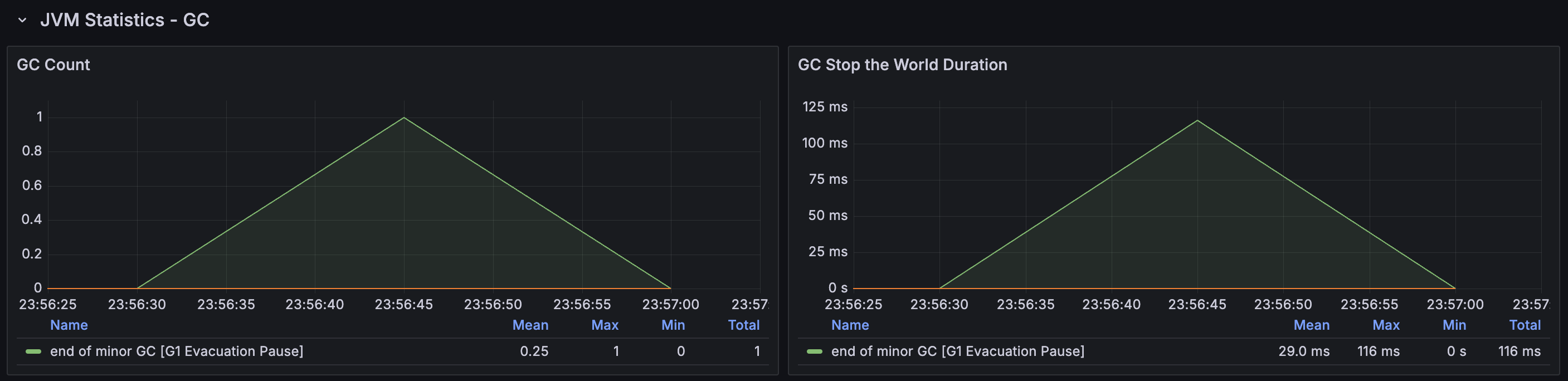
메모리 할당이 굉장히 낮은 것을 볼 수 있는데, 할당이 발생하는 경우는 다음 경우들밖에 없다. 특히, Local cache hit이 발생하는 경우에는 이미 이벤트 목록 데이터가 메모리에 존재하는 상황이므로 추가적인 할당이 발생하지 않는다. filterEvents에서 이 데이터를 참조만 하면 되는 것이다. 따라서 getEventsLocalCache 메서드에서 할당한 양은 MB 단위이다! 그리고 GC는 G1 Evacuation pause 단 한 번만 발생하였다.
1. getEventsLocalCache
(1) Local cache에 데이터가 없어, Redis에서 데이터를 조회해오는 경우
(2) 나머지 경우에는 추가적인 할당이 발생하지 않는다.
이벤트 목록 데이터는 Local cache를 통해 이미 메모리에 존재하기 때문이다.
→ 총 158.06 MB 사용
2. loadEvents : Redis에서도 데이터가 없어, DB에서 이벤트 목록을 조회해오는 경우
→ 총 14.79 GB 사용
3. filterEvents : 활성 상태인 이벤트를 필터링하는 경우
→ 총 103.71 MB 사용
정리
여기서 얻을 수 있는 인사이트는 다음과 같다.
1. Redis cache를 사용하는 경우에는 String 형에서 객체로 역직렬화하는 과정이 필요하기 때문에 메모리 할당이 2번 발생하는 것을 명심하자. Redis에서 가져오는 데이터가 작은 크기를 가졌다면 상관이 없겠지만, 큰 크기를 가졌다면 네트워크 bandwitdh 병목 문제와 더불어 메모리 압박량이 증가함으로써 발생하는 GC 관련 문제도 발생하게 된다.
2. 거대한 크기의 객체를 할당하는 것을 조심하자. Humongous object로 판단되는 순간 Memory fragmentation 문제가 함께 따라오며 Young GC가 자주 발생하게 되는 원인이 될 수 있기 때문인데, GC의 발생과 Application의 Response latency는 서로 직결되기 때문에 더욱 조심해야 한다. 특히, 큰 파일을 읽어야 할 때 한 번에 메모리에 빡 올리는 게 아니라 Stream으로 필요한 만큼만 조금조금씩 읽어오는 방식을 취하는 것이 좋을 것 같다.
'Server' 카테고리의 다른 글
| [Server] Redis & Local cache를 통한 조회 성능 개선기 (0) | 2025.02.18 |
|---|---|
| [Server] Redis Pub/Sub을 통해 Local cache 동기화하기 (0) | 2025.02.03 |
| [Server] Offset 기반 vs. Cursor 기반 Pagination (with nGrinder 부하 테스트) (0) | 2025.01.20 |
| REST API (0) | 2021.11.14 |
| API / HTTP Packet / HTTP Method (0) | 2021.11.07 |



