

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- redis
- mips
- 백준
- 프로세스
- 페이징
- 컴퓨터구조
- fork()
- 부동소수점
- local cache
- 페이지 부재율
- 세마포어
- 우선순위
- 스케줄링
- concurrency
- BOJ
- 스레드
- mutex
- 기아 상태
- 알고리즘
- PYTHON
- Algorithm
- 페이지 대치
- 단편화
- ALU
- garbage collection
- 교착상태
- 가상 메모리
- 인터럽트
- gc
- 운영체제
- Today
- Total
봉황대 in CS
[Server] Redis & Local cache를 통한 조회 성능 개선기 본문
현재 진행하고 있는 프로젝트에서 이벤트 조회 기능을 구현하며, 이 기능에 부하를 주었을 때 어떤 문제가 발생하는지를 확인하고 여러 가지 기법들을 적용해 보며 해결하게 되었다. 이 과정을 통해서 배웠던 것들을 여기에 정리하고자 한다.
상황 설명
각 이벤트에는 이벤트의 시작 시각(beginTime)과 종료 시각(endTime)이 저장된다.
@Getter
@Entity
@Table(name = "events")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Event extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long productId;
private String name;
private String description;
private String imageUrl;
private LocalDateTime beginTime;
private LocalDateTime endTime;
...
}
활성(Active) 이벤트는 아래의 조건을 만족하는 이벤트를 말한다.
시작 시각 <= 현재 시각 < 종료 시각
이러한 활성 이벤트들을 List 형태로 반환하는 '활성 이벤트 목록 조회 기능'을 구현하는 것이 목적이다.
방법 1. DB 조회
Table full scan
먼저, 가장 기본적인 방법으로 항상 DB에서 조회해 오도록 하였다.
select *
from events e
where e.begin_time <= :date
and e.end_time > :date
옵티마이저 실행 계획을 출력해 보면 당연하게도 Table full scan이 발생하고 있는 것을 볼 수 있다. 위 쿼리는 PK인 id에 대한 쿼리도 아닐뿐더러(MySQL 기준, PK에 대한 Clustered 인덱스는 자동으로 생성됨), beginTime과 endTime과 관련된 인덱스가 아무것도 존재하지 않기 때문이다.

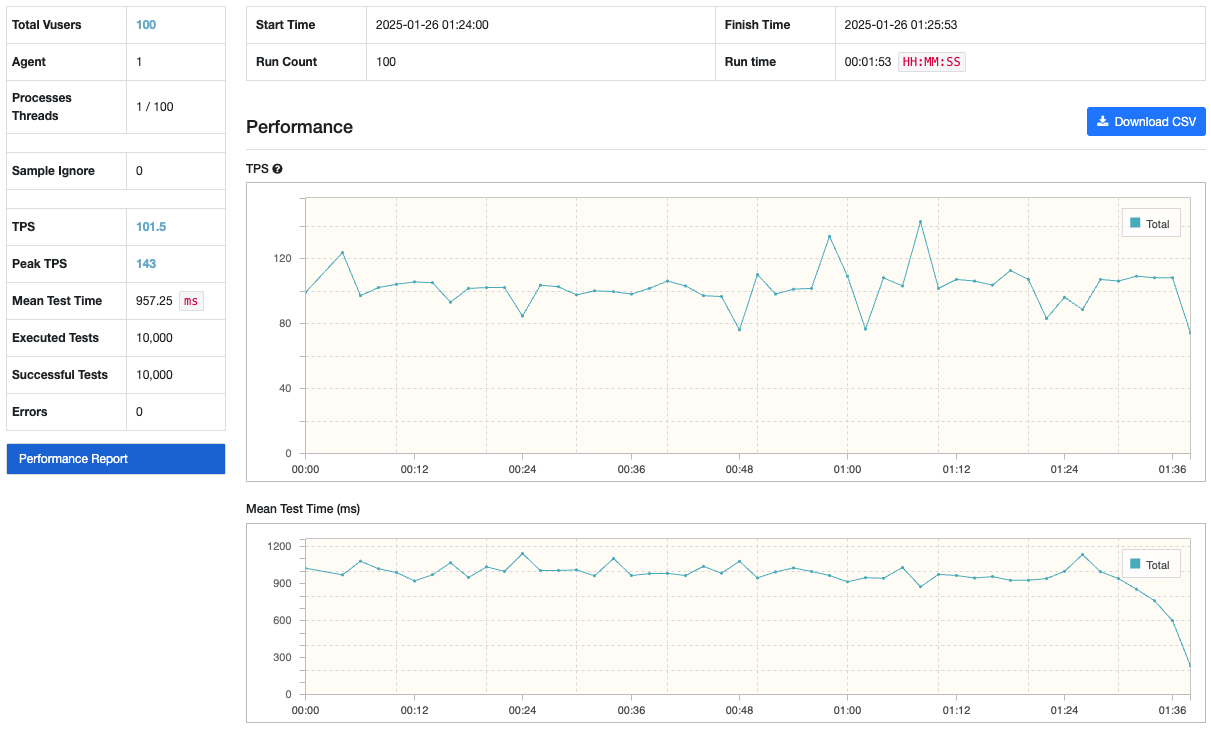
테이블에 존재하는 모든 데이터들을 하나하나 뒤져본 후에서야 결과가 반환되는 쿼리이므로 처리 속도가 매우 느릴 것으로 짐작할 수 있고, 실제로 nGrinder를 통해 부하 테스트를 진행하였을 때 평균 TPS가 31.3 밖에 되지 않았다.
Index range scan
그럼 인덱스를 타도록 하면 성능이 얼마만큼 향상될까? 시각 관련 정보들을 column으로 가지는 인덱스를 생성하고 쿼리에 힌트를 주어 이를 타도록 강제해 보았다.
create index time_index
on events (begin_time, end_time);select /*+ index(e time_index) */ *
from events e
where e.begin_time <= :date
and e.end_time > :date
평균 TPS는 101.5로, 이전보다 훨씬 향상되었지만 예상보다는 낮은 수치였다. 이전 Pagination 성능 개선 포스팅에서는 인덱스를 타게 함으로써 평균 621.7 TPS을 달성하였는데 이 수치에 비해서는 너무나도 낮다. 왜일까? (물론 반환해야 하는 데이터의 양이 더 커지긴 했음)
테이블의 데이터에 접근하는 방식(Random access vs. Sequential access)이 이러한 성능 차이를 만들어 낸 것으로 예상한다. Pagination의 경우에는 Clustered 인덱스를 탔고, Clustered 인덱스에 저장되어 있는 데이터의 순서는 테이블의 물리적인 저장 순서와 동일하다. Pagination에서의 요구사항은 기준 id를 시작으로 오름차순 100개를 반환하는 것이었으므로 인덱스를 타서 찾은 데이터의 시작 위치에서 연속적으로 위치한 데이터들을 반환하면 되었던 것이다. 즉, 테이블의 데이터들에 대해서 Sequential access만이 발생한 것이다. 반대로 이번 상황은 Random access가 다수 발생할 수밖에 없다. time_index에 데이터가 저장되어 있는 순서는 물리적 저장 순서와 다르기 때문이다.
따라서 쿼리 튜닝을 통해서는 성능 개선의 한계가 존재한다. 이뿐만 아니라, 활성 이벤트 목록 조회 기능은 굉장히 자주 불릴 것으로 예상되는 기능이기 때문에 DB에 항상 조회 요청을 보내는 방식은 바람직하지 않다. 이렇게 DB에게 부하를 많이 주게 된다면 동일 DB로 오는 다른 요청들이 커넥션을 얻기 위해 계속 대기하다가 Connection timeout이 발생하는 등 여러 서비스들이 영향을 받게 되기 때문이다.
방법 2. Redis를 Cache server로 두기
DB에게 매번 활성 이벤트 목록 조회 요청을 보내는 경우에는 그 쿼리 속도가 만족스럽지 않으며, 이는 자주 요청되는 기능이기 때문에 DB로 가는 부하를 최대한 줄여보고자 한다. 이때 이벤트 목록은 자주 갱신되지 않고 완벽히 실시간으로 갱신되지 않아도 괜찮은 데이터이므로, 이벤트 목록을 다른 시스템에 캐싱하여 조회하는 방안을 생각해 볼 수 있다. 이에 Redis를 Cache server로 두고 여기에 이벤트 목록을 캐싱하여 사용해 보았다. Key 값은 "events", value 값은 이벤트 목록을 담은 배열(정확히는 이를 String 형으로 변경한 형태)이다.
Redis는 In-memory DB이다. 사용할 수 있는 메모리 공간은 제한적이기 때문에 데이터를 효율적으로 저장하는 것이 중요하다. 그리고 데이터의 길이는 네트워크 송・수신에 걸리는 시간에 영향을 주는 요소이기도 하다. 따라서 2가지 최적화를 진행하였다. 첫 번째, 모든 이벤트들을 목록에 저장하여 Redis에 올리지 않고, 이벤트 종료 시각이 지금 시점(Redis에 데이터를 캐싱하는 시점) 보다 늦은 이벤트들만 저장하도록 하였다. 즉, 지금 이미 활성 상태인 이벤트들과 앞으로 활성 상태가 될 이벤트들만 Redis에 캐싱하는 것이다. 그리고 서버에서 현재 활성 상태인 이벤트들을 따로 필터링한 후에 클라이언트에게 반환할 것이다. 두 번째, Spring에서 제공하는 RedisSerializer를 사용하지 않고, 데이터 압축을 진행하여 Redis에 올리도록 GzipRedisSerializer를 구현하여 사용하였다. (→ 구현에 참고한 블로그이다! https://mangkyu.tistory.com/411) Spring에서 제공하는 GenericJackson2JsonRedisSerializer를 사용한 경우에 데이터 크기는 7.24MB였는데, GzipRedisSerializer를 사용하여 2.25MB로 줄여 저장할 수 있었다. (데이터 크기를 31%로 줄인 것 ㄷ)
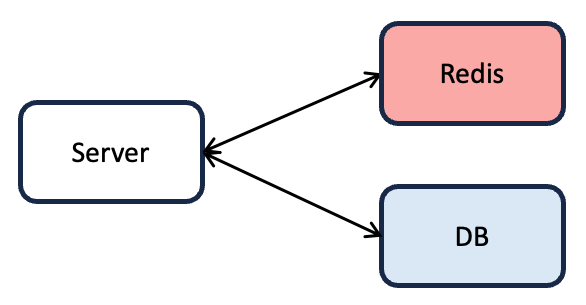
활성 이벤트 목록 조회 요청이 발생하는 경우에는 다음과 같은 로직이 수행된다. (Look-aside 방식)
1. Redis에서 Cache hit가 발생하는 경우
: 반환받은 배열을 필터링한 후 return
2. Redis에서 Cache miss가 발생하는 경우
(1) DB에서 이벤트 목록을 조회한다.
(2) 이벤트 목록을 Redis에 저장한다.
(3) 필터링한 후 return
이벤트에 갱신이 발생한다면 Redis에 현재 올라가 있는 데이터는 유효하지 않은 데이터가 되어 버린다. 이 경우에는 캐싱되어 있는 데이터를 아예 삭제해 버리도록 하였다. (Cache invalidation 방식)
이벤트에 갱신이 발생하는 경우
1. Redis에 올라가 있는 데이터를 삭제한다.
2. DB를 갱신한다.
→ 이후에 Cache miss가 나는 경우, 갱신된 데이터가 Redis에 올라가게 된다.
발생 문제 1. Cache miss가 발생하는 경우, DB 요청이 여러 번 발생
Redis에게 조회 요청이 동시에 여러 개 도착하였는데, 캐싱되어 있는 데이터가 없어서 Cache miss가 발생한 상황이라고 해보자. 위에서의 로직만을 따른다면, Cache miss라고 반환을 받은 모든 thread들이 일제히 DB에게 조회 요청을 보내게 될 것이다. 한 순간에 DB에게 부하가 증가하게 되는 것이다.
이 문제를 막기 위한 방안으로 Redis를 통한 분산 Lock을 둘 수 있다. Lock을 통해 단 하나의 thread만이 DB에게 요청을 보내고, 나머지 thread들은 데이터가 캐싱될 때까지 기다리게 하면 된다.
public static final String EVENTS_LOCK_KEY = "events-lock";
private List<Event> loadEvents(LocalDateTime now) {
Boolean lockIsAcquired = cacheManager.tryLock(EVENTS_LOCK_KEY);
if (lockIsAcquired.equals(Boolean.FALSE)) {
return retryLoadFromCache();
}
try {
List<Event> events = loadFromDb(now);
cache(events);
return events;
} finally {
cacheManager.releaseLock(EVENTS_LOCK_KEY);
}
}
tryLock과 releaseLock 메서드는 다음과 같이 구현되어 있다.
private static final String LOCK_VALUE = "locked";
public Boolean tryLock(String key) {
return redisTemplate.opsForValue().setIfAbsent(key, LOCK_VALUE);
}
public void releaseLock(String key) {
redisTemplate.delete(key);
}
아래는 Lock 획득에 실패했을 경우, 데이터가 캐싱될 때까지 대기하기 위한 메서드이다. 하지만 대기를 무한정할 수는 없으며 Redis에게 데이터가 존재하는지 계속 묻는 것도 리소스 낭비로 이어지게 된다. 따라서 지정한 횟수(MAX_RETRY_CNT)만큼만 Redis에게 질의를 보내며, 만약 데이터를 가져오지 못했을 경우에 대기 시간을 지수적으로 증가시키는 backoff를 적용하였다.
int MAX_RETRY_CNT = 10;
int INITIAL_DELAY_MSEC = 1_000;
int MAX_DELAY_MSEC = 100_000;
private List<Event> retryLoadFromCache() {
for (int attempt = 0; attempt < MAX_RETRY_CNT; attempt++) {
List<Event> events = loadFromCache();
if (events != null) {
return events;
}
backoff(attempt);
}
throw new CacheMissException();
}
private void backoff(int attempt) {
try {
int delay = Math.min(
INITIAL_DELAY_MSEC * (int) Math.pow(2, attempt - 1),
MAX_DELAY_MSEC);
TimeUnit.MILLISECONDS.sleep(delay);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
발생 문제 2. OOM 발생
이는 AWS EC2 프리티어쨩처럼 리소스가 극한의 상황일 때에만 발생할 수도 있는 문제이다. nGrinder 부하 테스트로 100개의 Virtual user가 요청을 동시에 보내도록 하였더니 서버가 OOM을 뱉으며 죽어버렸다 .. (참고로 부하 테스트에서는 데이터 조회 요청만 보내고, 데이터 추가나 갱신은 진행하지 않는다.)
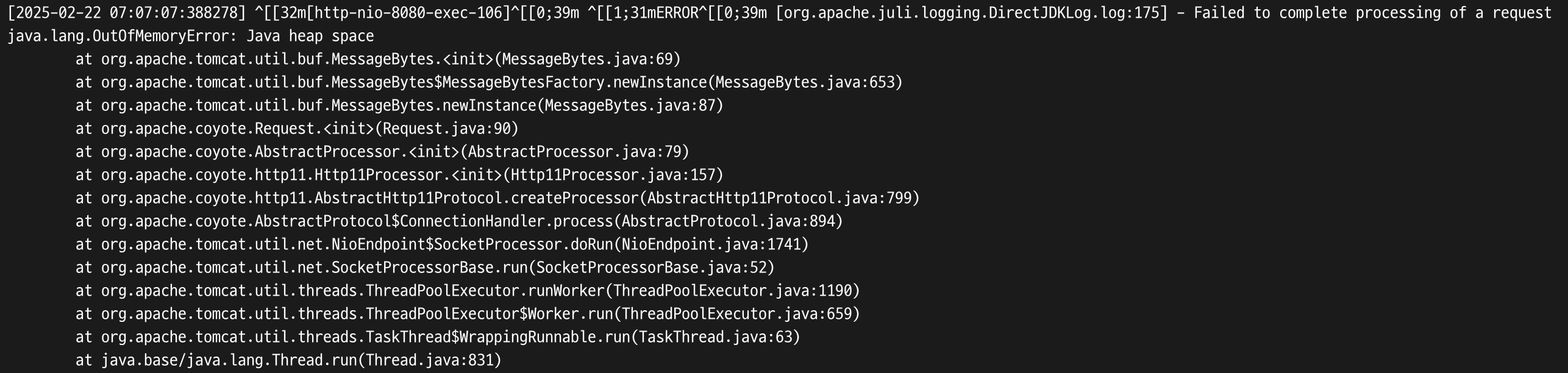
원인은 RedisSerializer에서 deserialize 메서드 호출 시, 인자를 byte 배열로 받기 때문에 원래 데이터 크기보다 큰 공간을 할당했기 때문으로 예상한다.
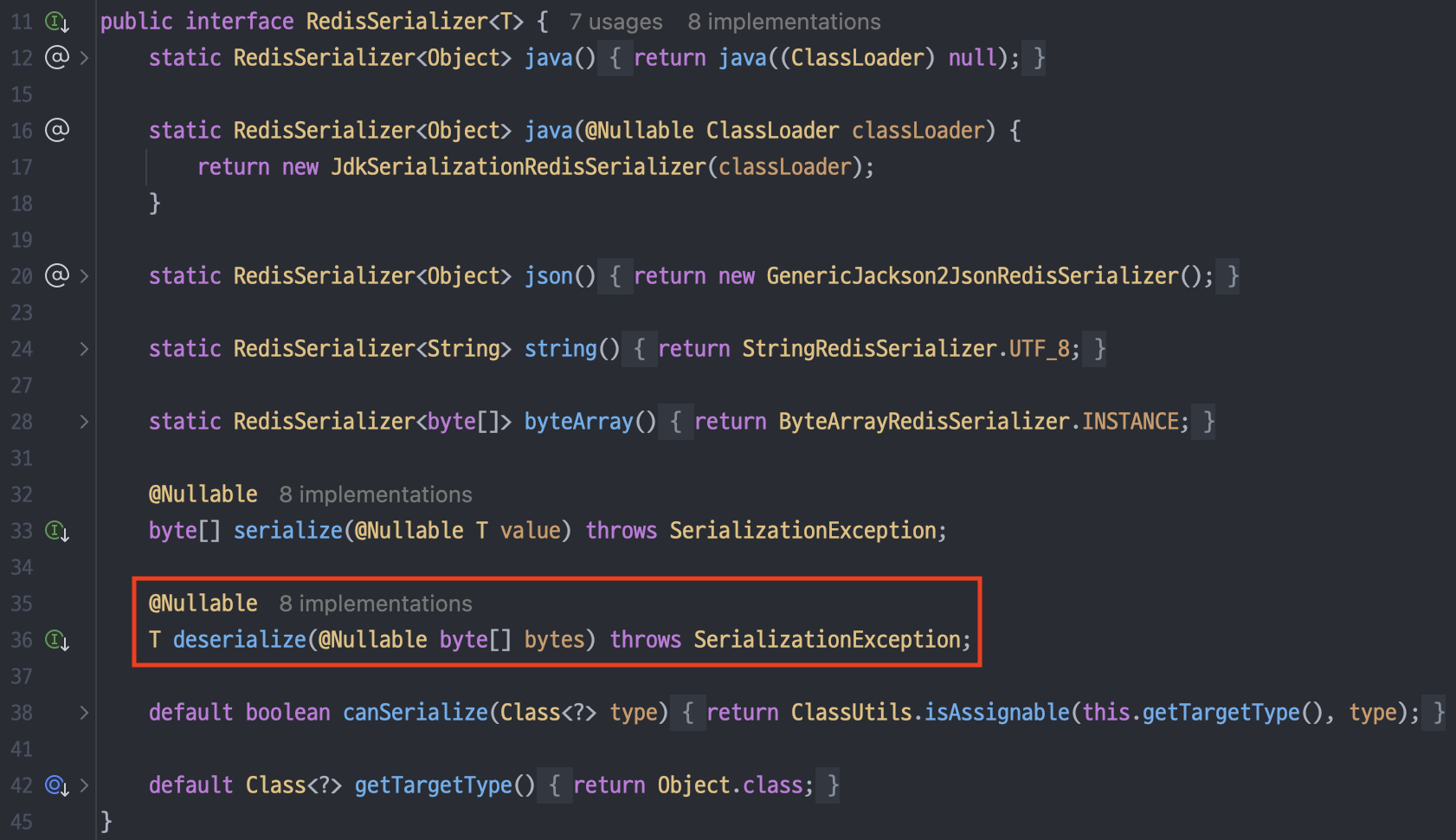
발생 문제 3: RedisCommandTimeoutException 발생
문제 2번 발생 후, nGrinder 부하 테스트에서 Virtual user를 20개로 줄였더니 발생한 문제이다. 이것도 AWS ElastiCache for Redis처럼 매우 연약한 녀석을 사용할 때에만 발생할 수도 있는 문제이다 ..
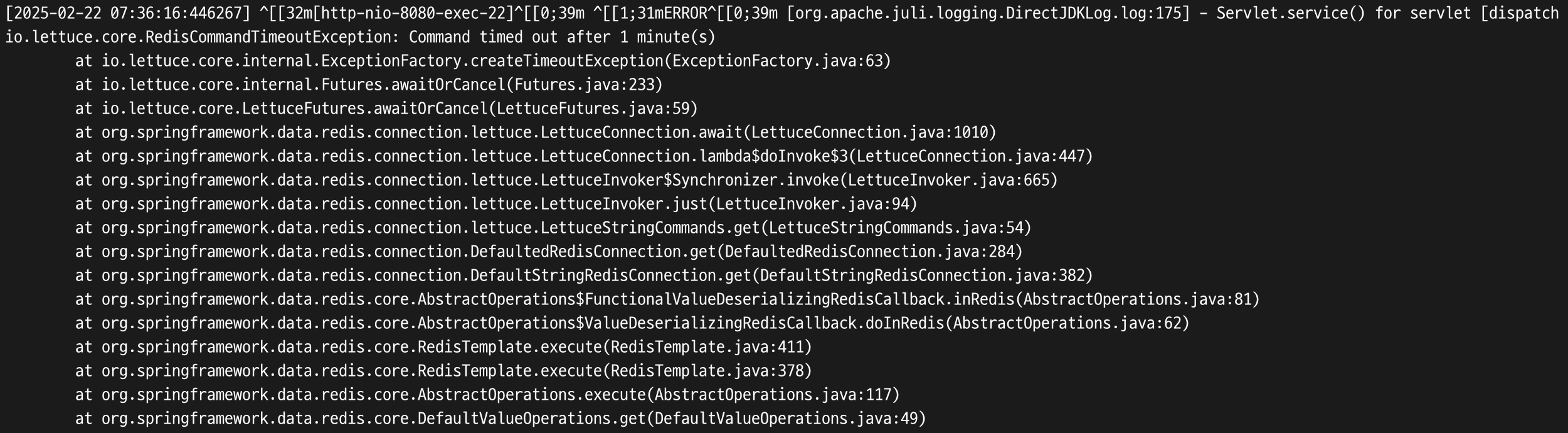
예상되는 원인은 Redis에게 부하가 너무 많이 갔고, 데이터를 네트워크를 통해 보내는 데에 시간이 너무 오래 걸려서 Timeout이 발생한 것이다. Redis는 single thread로 동작하기 때문에 만약 엄청 오래 걸리는 연산이 발생한다면 나머지 요청들은 그 연산이 끝날 때까지 전부 대기하고 있어야 한다는 문제가 존재하는데, 이를 보여주는 예시이지 않을까 생각한다.
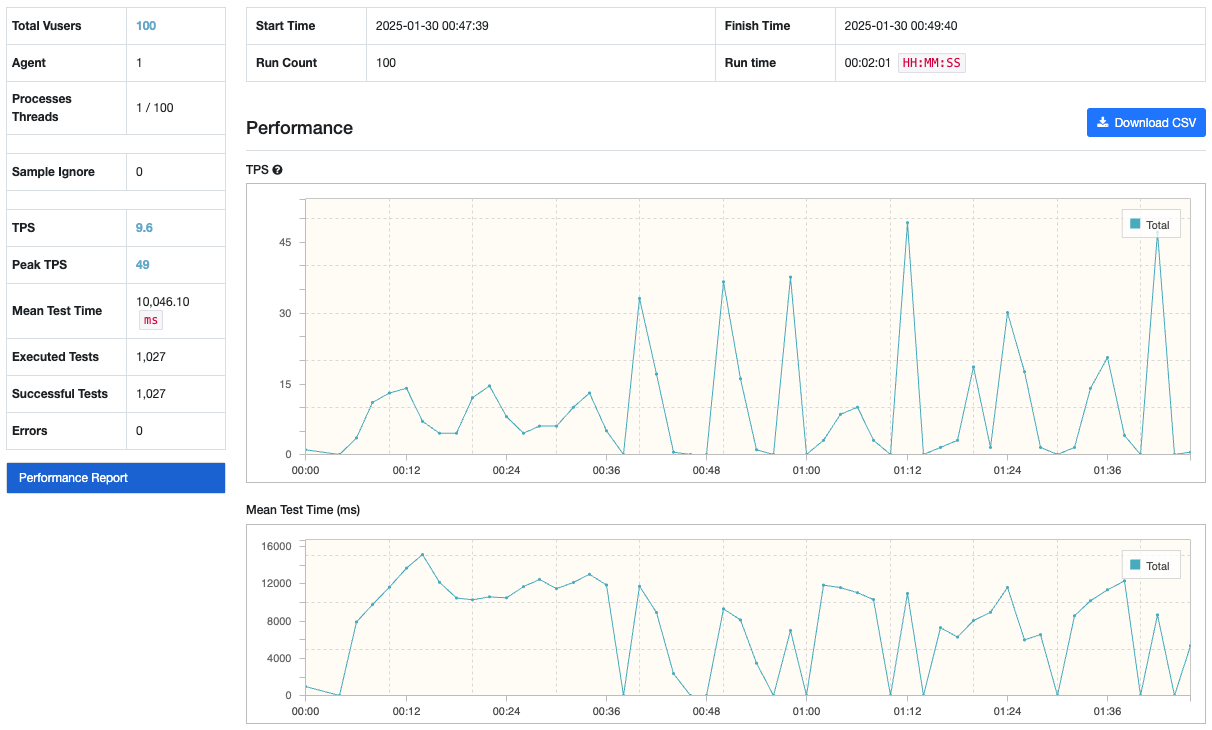
이러한 문제들의 발생으로 AWS 프리티어쨩들에서 부하 테스트를 진행하는 것은 불가능하다고 판단되었다. 따라서 나의 M1 맥북에서 테스트를 진행하였고, 평균 TPS는 9.8 정도로 매우 낮은 것을 확인하였다.
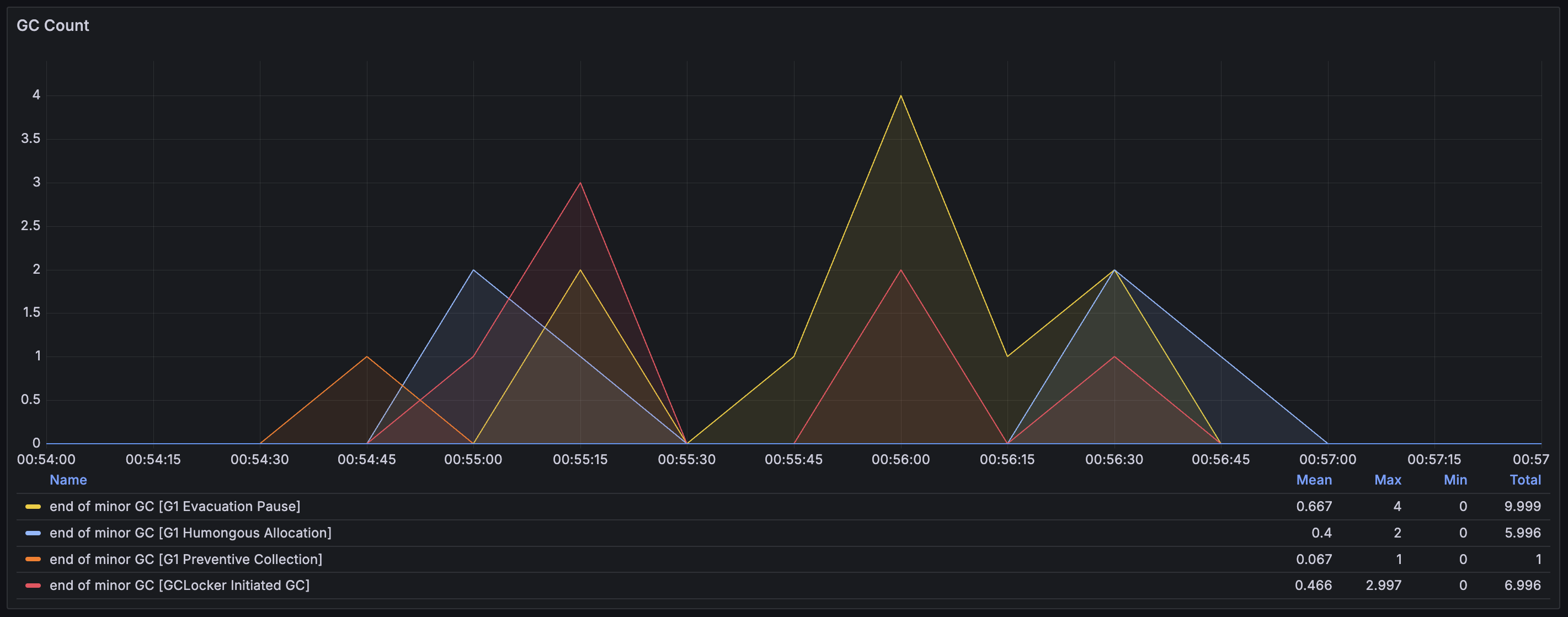
그리고 Grafana로 모니터링한 결과, GC도 굉장히 자주 발생하는 것을 확인할 수 있었다. 메모리 할당과 해제가 매우 빈번히 발생하고 있다는 것이다. (DB 조회 때는 GC가 이런 양상으로 발생하지 않는데, 왜 여기에서만 대량으로 발생하는지는 더 찾아봐야겠다.)
→ 250411 추가 : https://eunajung01.tistory.com/179
성능도 그렇고 상당히 많은 문제들이 발생하였지만 .. Redis를 Cache server로 사용한 방안의 가장 큰 문제는 DB로 가는 부하를 Redis로 옮긴 것일 뿐이라는 것이다. 문제 3번에서 본 것처럼 만약 Redis가 이 부하를 견뎌주지 못한다면 아예 서비스를 하지 못하는 상황까지 갈 수 있다.
방법 3. Local cache + Redis cache server (2-level caching)
이벤트에 대한 데이터는 Global 데이터이다. 즉, 어느 사용자 한 놈에게만 국한된 데이터가 아닌, 모두가 동일하게 바라보는 데이터라는 것이다. 따라서 이벤트 목록 데이터는 Local cache를 활용하기에 매우 적합하다. Local cache는 서버마다 자신의 메모리 등에 따로 저장하는 캐시로, 서버 내에 데이터를 캐싱하고 이를 조회하는 것이기 때문에 조회 속도가 매우 빠르다. 이로써 데이터 조회 시 네트워크 통신 횟수를 줄이면서 성능 상의 이점을 얻고, 위의 2번 방법에서 사용한 Redis cache server를 그대로 사용하는 2-level caching을 통해 DB로 가는 요청을 최대한 줄였다.
이때 가장 문제가 되는 것은 현재 Local cache에 캐싱된 데이터가 갱신이 필요한지 그 여부를 어떻게 알 수 있느냐인데, 이는 Redis Pub/Sub과 Spring scheduler를 통해서 해결하였다. → 관련 포스팅 : https://eunajung01.tistory.com/172
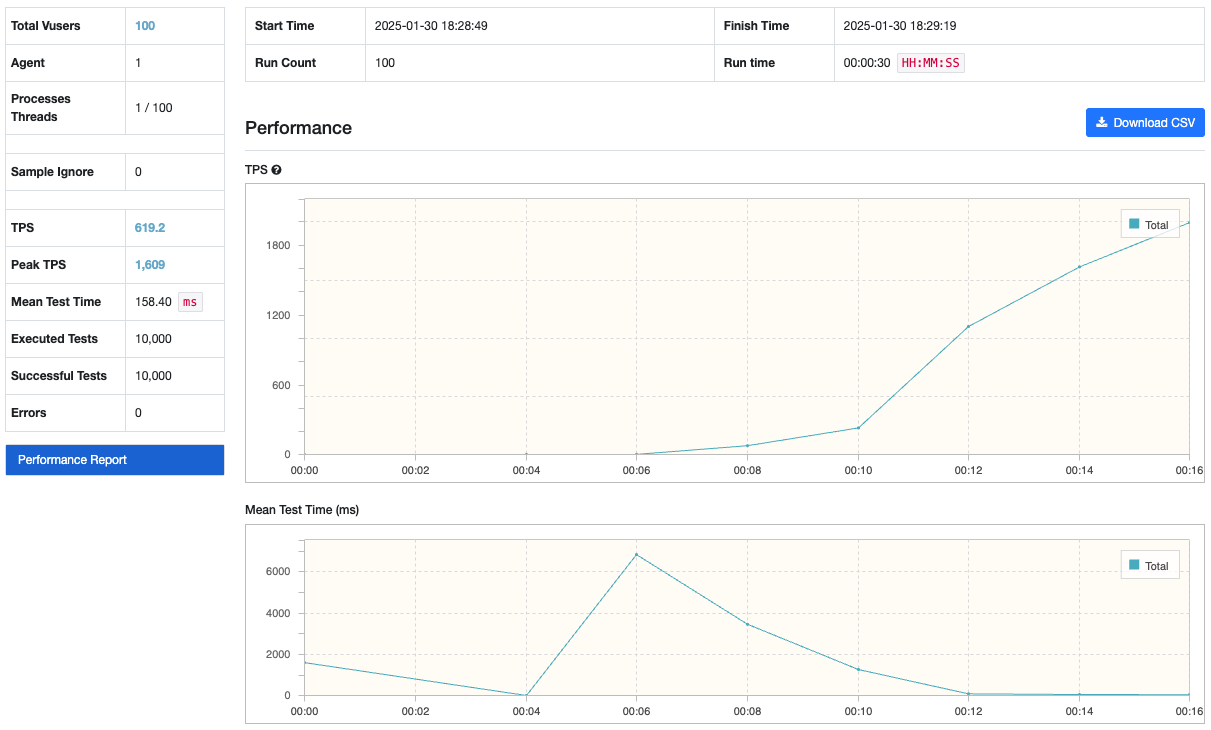
아래는 M1 맥북에서 부하 테스트를 실행한 결과이다. 서버의 메모리에 저장되어 있는 데이터를 조회하는 것이므로 GC 또한 발생하지 않는 것을 확인하였다.
정리
DB 요청을 최대한으로 줄이고 조회 성능을 개선하기 위한 긴 여정이었다. 가장 중요한 것은, 여기선 해결 방안으로 캐시를 사용하였지만 이는 이벤트 목록 데이터가 '자주 갱신되지 않고 완벽히 실시간으로 갱신되지 않아도 괜찮은 데이터'라는 전제가 깔려있었기 때문에 가능했던 것이다. 만약 반대의 성향을 가지는 데이터였다면 이를 캐싱하는 방안은 적합하지 않다. 그렇다면 완벽히 실시간으로 갱신되어야 하는 데이터에 대해서는 어떤 방안이 적합한가 ?? 이 쪽에 대해서는 공부가 더 필요할 것 같다. (+ JVM의 GC 쪽 공부도 필요..)
'Server' 카테고리의 다른 글
| [Server] 왜 Redis cache 사용 시 GC가 자주 발생할까? (0) | 2025.04.11 |
|---|---|
| [Server] Redis Pub/Sub을 통해 Local cache 동기화하기 (0) | 2025.02.03 |
| [Server] Offset 기반 vs. Cursor 기반 Pagination (with nGrinder 부하 테스트) (0) | 2025.01.20 |
| REST API (0) | 2021.11.14 |
| API / HTTP Packet / HTTP Method (0) | 2021.11.07 |



