
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 프로세스
- 기아 상태
- Algorithm
- mips
- 인터럽트
- BOJ
- 백준
- 우선순위
- PYTHON
- fork()
- 단편화
- concurrency
- 페이지 대치
- ALU
- 스레드
- 동기화
- 알고리즘
- 세마포어
- 교착상태
- 페이징
- 운영체제
- 스케줄링
- 가상 메모리
- 컴퓨터구조
- 트랩
- Oracle
- 페이지 부재율
- 부동소수점
- 추상화
- mutex
- Today
- Total
봉황대 in CS
[Oracle] SQL Processing - Library Cache, Soft parse vs. Hard parse 본문
[Oracle] SQL Processing - Library Cache, Soft parse vs. Hard parse
등 긁는 봉황대 2024. 9. 20. 01:14* 본 글은 ‘친절한 SQL 튜닝’ 책과 Oracle 공식 문서들을 바탕으로 작성하였습니다. (참고한 문서의 링크는 하단에 첨부)
SQL Processing 과정 중에서 Soft parse와 Hard parse는 각각 어떤 과정이고, 언제 선택되는가?
먼저 여기에서 중심이 되는 구조인 Library cache에 대해서 알아보자.
Library Cache
SQL과 PL/SQL code를 재사용할 수 있도록 caching 해두는 메모리 공간이다.
System Global Area(SGA) 내부 Shared pool에 위치하여, 모든 server와 background process가 공유한다.

Why caching & reusing SQL, PL/SQL codes ?
왜 SQL과 PL/SQL code를 caching 해서 재사용하려고 할까?
Optimizer는 SQL 최적화를 하기 위해서 다음의 일을 진행한다.
1. Data dictionary에 미리 수집해둔 System 통계 정보와 Object 통계 정보를 바탕으로
다양한 실행 경로를 생성하고, 각 경로의 예상 비용을 산정한다.
- System 통계 정보 : CPU 속도, Single block I/O 속도, Multiblock I/O 속도 등
- Object 통계 정보 : Table 통계, Index 통계 등
- 이외에도 Optimizer가 사용하는 정보는 더 많이 존재한다.
2. 생성한 실행 경로들끼리 예상 비용을 비교한 후, 가장 효율적인 하나를 선택한다.
이때, 하나의 query를 수행하는 데 있어 후보군이 될만한 수많은 실행경로를 도출하고,
짧은 순간에 dictionary와 통계 정보들을 읽어 각각에 대한 효율성을 판단하는 과정은 매우 무겁다.
즉, CPU를 많이 소비하는 작업이라는 것인데, 매번 이 작업을 진행한다면 성능이 매우 하락될 것이다.
따라서 cache에 저장되어 있는 가장 효율적이라고 선택되었던 놈을 바로 재사용함으로써
성능 상의 이점을 얻기 위한 장치인 것이다.
그렇다면 SQL은 어떤 과정을 통해서 실행되고, Library cache를 어느 시점에 확인할까?
만약 user가 SQL 문을 제출하면,
- 먼저 DBMS는 SQL을 parsing 하고,
- 해당 SQL이 Library cache에 존재하는지 확인한다.
Library cache hit를 하느냐, miss를 하느냐에 따라 이후 과정이 2가지로 나뉘게 된다.
조금 더 자세히 알아보면 ..
SQL Processing
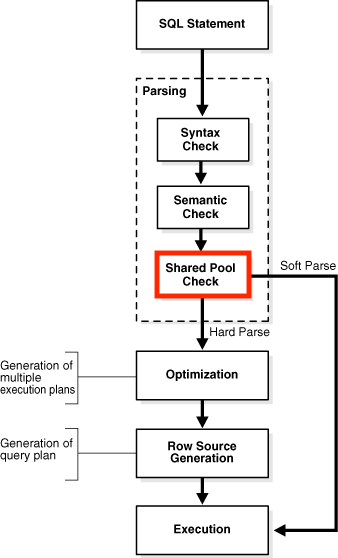
Syntax Check & Semantic Check
- Parse tree를 생성해서
- Syntax check : 문법적 오류가 없는지 확인하고,
e.g., 사용할 수 없는 keyword를 사용했는가? 순서가 올바른가? 누락된 keyword가 존재하는가? - Semantic check : 의미상 오류가 없는지 확인한다.
e.g., 존재하지 않는 table을 사용했는가? 사용한 object에 대한 권한이 존재하는가?
Shared Pool Check
Library cache에 동일 SQL 문이 존재하는지 확인하는 과정이다.
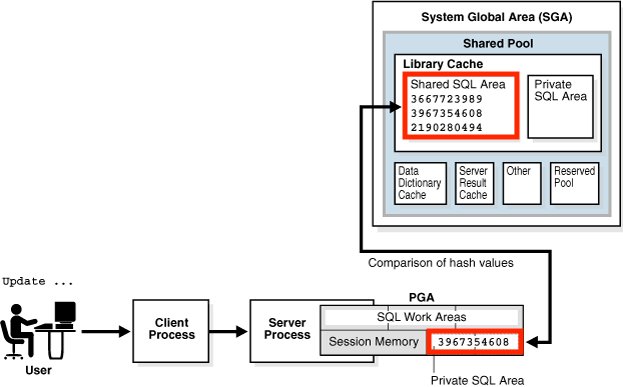
[참고] Process Global Area(PGA) : Oracle server process에 할당된 고유 메모리 영역
1. Hashing algorithm을 사용해서 실행하려는 SQL에 대한 SQL ID를 얻는다.
- 이 값은 V$SQL.SQL_ID에서 확인할 수 있는 고유한 값이다.
- For a specific SQL statement, the unique identifier of the parent cursor in the library cache.
A hash function applied to the text of the SQL statement generates the SQL ID.
2. SQL ID를 기준으로 Library cache를 탐색한다.
- 만약 동일한 SQL ID가 존재한다면, 동일한 SQL이 caching 되어 있다는 것과 같다.
이때 Library cache hit / miss 여부에 따라 Soft parse와 Hard parse로 나뉘게 된다.
여담으로 .. SQL ID는 SQL 전체 텍스트와 1:1 대응 관계를 갖는다.
SQL 텍스트가 변하면(소문자, 대문자 차이에도 불구하고), 그에 따라 SQL ID도 변한다는 것이다.
Soft Parse
Library cache hit, 즉 Library cache에 동일한 SQL이 caching 되어 있는 경우에 진행된다.
곧바로 실행 단계(Execution)로 넘어가, SQL engine이 이전의 실행 계획을 재사용한다.
Hard parse에 존재하는 복잡하고 무거운 과정들을 아예 뛰어 넘는 것이다.
Hard Parse
Library cache miss, 즉 Library cache에 동일한 SQL이 caching 되어 있지 않은 경우에 진행된다.
- Optimization
: Optimizer가 해당 SQL 문에 대해 여러 실행 경로들을 뽑고, 가장 효율적인 놈을 선택한다. - Row source generation
: 선택된 실행 계획을 통해 Iterative execution plan을 생성하여 SQL engine이 실행할 수 있도록 한다. - Execution
이후 포스팅 계획 ..
이번 포스팅은 사실 다른 주제로 작성하고 있었던 글인데 (SQL Processing 부분은 빌드업 부분이었음)
작성하면서 문서들을 더 찾아보던 중에 생각보다 더 복잡한 메커니즘이 존재하는 것을 깨달아버려..
일단 이번 포스팅은 요정도로 마무리하기로 했다.
왜 이 쪽을 들여다보게 되었냐면, 최근에 Oracle SQL tuning을 직접 실습해보고 있는데
실행 계획들을 뽑아보면 맨 위 뜨는 ‘Plan hash value’ 이 놈이 무엇인지 알아내려고 했었다.
Plan hash value: 3441279308
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 99733 | 10M| 204 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| MEMBER | 99733 | 10M| 204 (0)| 00:00:01 |
----------------------------------------------------------------------------
Plan hash value는 어떤 SQL 문에 대해 생성된 특정 실행 계획의 hash 값으로, 각 실행 계획을 고유하게 식별하는 값이다.
Library cache hit 시, caching 되어 있는 실행 계획으로 넘어가기 위한 장치인가???? 하고 문서들을 더 찾아보고 있었는데
완전 NO 였음 ;;
이번에 문서들을 찾아보면서 궁금증이 생긴 부분 + 더 자세히 알아둘 필요성이 있어보이는 부분들은 다음과 같다.
- Shared pool check 과정에서 동일한 SQL ID를 찾은 경우, 이전 실행 계획으로 어떻게 넘어가는가?
→ Library cache에 저장되어 있는 구조, Cursor sharing (Parent cursor, Child cursor 관련 ..) 등 - Row source generation 과정 & Execution 과정
→ Row source, Row source tree 등 - sql_id vs. hash_value vs. plan_hash_value
: 서로 어떤 차이가 있는 것인지 아직 잘 와닿지 않는다.
차차 공부하고 정리해서 블로그에 남겨보갔으.
참고
- https://docs.oracle.com/en/database/oracle/oracle-database/23/dbiad/db_sharedpool.html
- https://docs.oracle.com/en/database/oracle/oracle-database/23/cncpt/memory-architecture.html#GUID-079064A0-DBFC-45C4-B10A-1442D4667036
- https://docs.oracle.com/en/database/oracle/oracle-database/23/tgsql/sql-processing.html#GUID-B3415175-41F2-4EBB-95CF-5F8B5C39E927
- https://docs.oracle.com/en/database/oracle/oracle-database/23/tgsql/glossary.html#GUID-894D17CF-F10C-4BD5-B2A2-E3AC23759B78
'Computer Science & Engineering > Database' 카테고리의 다른 글
| [Concurrency Control] Index-locking Protocol: The Way to Prevent Phantom Reads (0) | 2024.08.12 |
|---|---|
| [Database] Isolation Levels (4) | 2024.08.11 |
| [Oracle] Latch vs. Lock ?? (0) | 2024.07.27 |
| [Oracle] Database Physical & Logical Storage Structures (4) | 2024.07.02 |
| [Concurrency Control] Optimistic Version Locking (2) | 2024.06.10 |


