
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- mutex
- 가상 메모리
- fork()
- 컴퓨터구조
- redis
- gc
- 기아 상태
- 알고리즘
- 스레드
- 우선순위
- 운영체제
- 인터럽트
- local cache
- Algorithm
- 백준
- 프로세스
- 부동소수점
- 페이징
- BOJ
- ALU
- 스케줄링
- 페이지 부재율
- garbage collection
- 단편화
- concurrency
- 페이지 대치
- 세마포어
- mips
- 교착상태
- PYTHON
- Today
- Total
봉황대 in CS
[Database] Isolation Levels 본문
ACID는 데이터베이스의 transaction이 안전하게 수행되는 것을 보장하기 위해서 가져야 하는 특성들을 말한다.
- Atomicity ensures that either all all the effects of a transaction are reflected in the database, or none are;
a failure cannot leave the database in a state where a transaction is partially executed. (All or nothing) - Consistency ensures that if the database is initially consistent,
the execution of the transaction (by itself) leaves the database in a consistent state. - Isolation ensures that concurrently executing transactions are isolated from one another,
so that each has the impression that no other transaction is executing concurrently with it.
(Concurrent transactions must not affect each other.) - Durability ensures that once a transaction has been committed,
that transaction’s updates do not get lost, even if there is a system failure.
이 글에서는 ACID 중 I를 담당하는 Isolation이라는 놈에 대해서 파헤친다.
각 ACID property에 대한 더 자세한 내용은 아래 링크 참고
https://github.com/IT-Book-Organization/Database-System-Concepts/tree/main/Part_07/Chapter_17
Serializability & Serializable schedule
Serializability, 직렬성은
여러 transaction이 동시에 자신의 일을 수행한 결과와
한 번에 한 transaction만이 순차적으로(직렬적으로) 자신의 일을 수행한 결과가 같도록 보장하는 특성을 말한다.
Serializability ensures that concurrent executions maintain consistency.
다시 말하자면, serializability의 목적은
동시에 실행된 여러 transaction의 결과가 그 transaction들이 순차적으로 하나씩 실행된 결과와 동일하게 만드는 것이고,
이를 보장하는 transaction schedule을 serializable schedule이라고 한다.
Serializability를 보장하기 위해서는 동시 실행되는 transaction들이 서로에게 영향을 주지 않도록 해야 한다.
따라서 'Serializability를 보장한다'는 것은 'Transaction들끼리 isolation 정도가 높다, 서로 강하게 고립되어 있다',
'ACID 중 Isolation property를 강하게 보장한다'는 것과 같다
But .. Ensuring serializability may allow too little concurrency
Serializable schedule이 높은 성능(throughput)까지 가지는 것은 매우 어려운 일이다.
특히 reader와 writer가 동시에 존재하는 경우에 serializability를 보장하기 위해서는
무조건 한 번에 한 놈만 자신의 일을 수행할 수 있도록 줄을 세워야 한다.
만약 먼저 실행된 놈이 엄청나게 긴 transaction이었다면,
나머지 한 놈은 그놈이 끝날 때까지 주구장창 기다려야 하기 때문에 특정 application에서는 이 부분이 커다란 문제가 될 수 있다.
정리하자면, application의 특성에 따라서
다른 transaction과 어느 정도는 nonserializable 하게 두는 것이 필요한 경우도 존재한다.
Transaction 끼리의 isolation의 정도를 느슨하게 둘 필요가 있는 것이다.
ANSI SQL Standard
ANSI(American National Standards Institute)에서는 'Isolation level'이라는 표준을 규정한다.
'4.32 SQL-transactions’에 정의되어 있다. : web.cecs.pdx.edu
- Isolation level : How transactions(T_1, T_2) are isolated from each other.
- Related to each isolation levels, they also have some violations.
(It’s about which isolation level is strict and which one has some violations allowed.)
| Isolation Level \ Violations | Dirty Read | Non-repeatable Read | Phantom Read |
| Read Uncommitted | O | O | O |
| Read Committed | X | O | O |
| Repeatable Read | X | X | O |
| Serializable | X | X | X |
O : May occur. / X : Don’t occur.
표에서 아래 행일수록 isolation level이 높은 것인데, 허용하는 violations도 적어지는 것을 볼 수 있다.
Isolation level이 높아질수록 serializability는 더 엄격하게 보장되고, transaction들 간의 isolation 정도가 높아지는 것이다.
우선은 총 3가지 violations가 각각 어떤 현상들을 말하는 것인지를 알아보고, 그다음에 각 isolation level들에 대해서 알아보자.
Read Phenomena (i.e., Violations)
T_1는 writer, T_2는 reader라고 하자.
Dirty Read
A transaction reads data written by other concurrent uncommitted transaction.
T_2는 T_1이 아직 commit 하지 않은 데이터를 읽을 수 있다.
e.g., Balance [X]: $100일 때, T_1과 T_2가 각각 다음의 일을 한다고 하자.
- T_1 : X := X - $20
- T_2 : read X
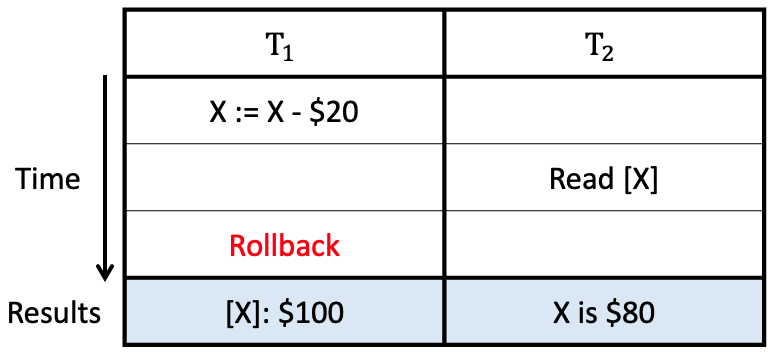
→ T_2는 T_1의 중간 값인 $80을 읽었다.
Non-repeatable Read
A transaction reads the same row twice and sees different value
because it has been modified by other committed transaction.
T_2는 T_1이 commit 하기 전 데이터와, commit을 한 후의 데이터를 읽을 수 있다.
따라서 T_2에서 두 번의 read가 발생했다면, 그 결과는 서로 다를 수 있다. (관점 : row 하나)
e.g., Balance [X]: $100일 때, T_1과 T_2가 각각 다음의 일을 한다고 하자.
- T_1 : X := X - $20
- T_2 : read X twice

→ T_2에서 발생한 두 번의 read는 서로 다른 값을 보았다.
Phantom Read
A transaction re-executes a query to find rows that satisfy a condition and sees a different set of rows,
due to changes by other committed transaction.
T_2는 T_1이 commit 하기 전 데이터와, commit을 한 후의 데이터를 읽을 수 있다.
따라서 T_2에서 두 번의 read가 발생했다면, 그 결과 집합은 서로 다를 수 있다. (관점 : row 집합)
e.g., T_1과 T_2가 각각 다음의 SQL을 실행한다고 하자.
# T_1
insert into instructor values(11111, 'Feynman', 'Physics', 94000);
# T_2 executes this twice.
select *
from instructor
where dept_name='Physics';
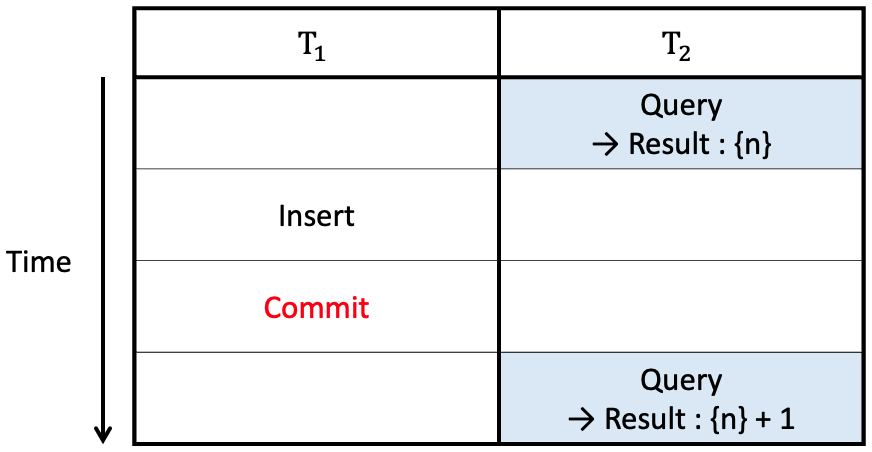
→ T_2에서 발생한 두 번의 select query는 서로 다른 결과 집합을 가진다.
Isolation levels
위의 현상들을 이해했다면, 이제 각 isolation level들이 무엇을 의미하는지도 이해할 수 있다!
| Isolation Level \ Violations | Dirty Read | Non-repeatable Read | Phantom Read |
| Read Uncommitted | O | O | O |
| Read Committed | X | O | O |
| Repeatable Read | X | X | O |
| Serializable | X | X | X |
Isolation level이 낮은 것부터 설명하자면 ..
Read Uncommitted
Can see data written by uncommitted transaction.
Uncommitted data를 읽을 수 있으므로, 3가지 phenomena가 전부 발생할 수 있다.
Read Committed
Only see data written by committed transaction.
Committed data만을 읽을 수 있기 때문에 dirty read는 발생하지 않는다.
하지만 commit이 발생하기 전과 후의 데이터를 전부 볼 수 있어서 Non-repeatable read가 발생할 수 있으며,
관점이 한 row에 대해서만 머물러 있기 때문에 Phantom read가 발생할 수 있다.
Repeatable Read
Same read query always returns same result.
Transaction 동안 commit 이전의 데이터 또는 commit 이후의 데이터만을 읽도록 강제하기 때문에
Non-repeatable read가 발생하지 않는다.
하지만 여기서도 관점이 한 row에 대해서만 머물러 있기 때문에 Phantom read가 발생할 수 있다.
Serializable
Can achieve same result if execute transactions serially in some ordered instead of concurrency.
Phantom read가 발생하지 않으려면 reader와 writer가 공존하면 안 된다.
즉, transaction의 실행 순서를 정해서 무조건 순차적으로 실행해야 한다.
Isolation level과 read phenomena에 대해서 공부하면서 들었던 궁금증은 ..
Phantom read는 여러 row들에 대해서 발생하는 것인데, 이를 어떤 알고리즘으로 방지하는지였다. (실질적인 방법이 궁금쓰)
요거슨 추후 포스팅으로 풀어보겠다.
→ https://eunajung01.tistory.com/167 (240812 추가)
그리고 찾아보니, 지금 포스팅으로 설명한 isolation level은 SQL standard이고,
Oracle, MySQL, PostgreSQL 등 각각이 지원하는 isolation level은 서로 다른 것으로 보인다.
Oracle : https://docs.oracle.com/cd/A91202_01/901_doc/server.901/a88856/c21cnsis.htm#2570
이것도 나중에 각각 찾아보면서 정리하면 좋을 것 같다.
참고
Database System Concepts - 7th Edition
ACID Properties in Databases With Examples
Isolation Levels in Database Management Systems
[Backend #9] Understand isolation levels & read phenomena in MySQL & PostgreSQL via examples
'Database' 카테고리의 다른 글
| [Oracle] SQL Processing - Library Cache, Soft parse vs. Hard parse (2) | 2024.09.20 |
|---|---|
| [Oracle] Latch vs. Lock ?? (0) | 2024.07.27 |
| [Oracle] Database Physical & Logical Storage Structures (4) | 2024.07.02 |
| [Concurrency Control] Optimistic Version Locking (2) | 2024.06.10 |
| Bottom-Up Build of a B+-Tree (Bulk-Loading) (4) | 2024.01.01 |


