

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 우선순위
- 교착상태
- 스레드
- 가상 메모리
- 알고리즘
- mips
- 부동소수점
- 인터럽트
- concurrency
- Algorithm
- ALU
- 페이지 부재율
- 프로세스
- 단편화
- 운영체제
- 페이지 대치
- 백준
- 트랩
- 스케줄링
- 동기화
- 페이징
- PYTHON
- 기아 상태
- 세마포어
- 추상화
- Oracle
- mutex
- fork()
- BOJ
- 컴퓨터구조
- Today
- Total
봉황대 in CS
XIndex: A Scalable Learned Index for Multicore Data Storage 본문
PPoPP '20
XIndex | Proceedings of the 25th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming
PPoPP '20: Proceedings of the 25th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming February 2020 454 pages Copyright © 2020 ACM Permission to make digital or hard copies of all or part of this work for personal or classroom use is
dl.acm.org
Learned Index
The Key Idea
- Using simple learned models (e.g., linear models, single-layer NNs)
(1) to approximate the CDF of keys’ distribution and (2) predict record positions. - Staged model architecture(Recursive Model Indexes, RMI) to reduce the leaf stage model’s computation cost.
- Train the model with records’ keys and their positions.
- fixed-length key-value records
- sorted in an array
- Use the model to predict the position with the given key.
Limitations
- Learned index doesn’t support any modifications: inserts, updates, removes.
- → needs to reconstruct the layout & retrain the model to handle every write request
- → concurrency problem occurs
- The performance is tied closely to workload characteristics. (both data distribution and query distribution)
- Learned index assumes the workload has a relative static query distribution,
but queries in real-world workloads tend to be skewed. - Learned index trains & predicts by the min & max prediction errors of the model.
- Learned index assumes the workload has a relative static query distribution,
- With small datasets, learned index’s performance is limited by the model computation cost.
An Intuitive Solution to Provide Writes:
- Buffer all writes in a delta index.
- Periodically compact it with the learned index. (compaction : merge the data → retrain the models)
but..
- Severe slowdown occurs for queries by looking up delta index first, and then the learned index.
- Concurrent requests are blocked by the compaction.
Needs update in-place with a non-blocking compaction scheme!
but.. correctness issue occurs

XIndex
- A scalable and concurrent learned index.
- Data structure adjustment according to runtime workload characteristics.
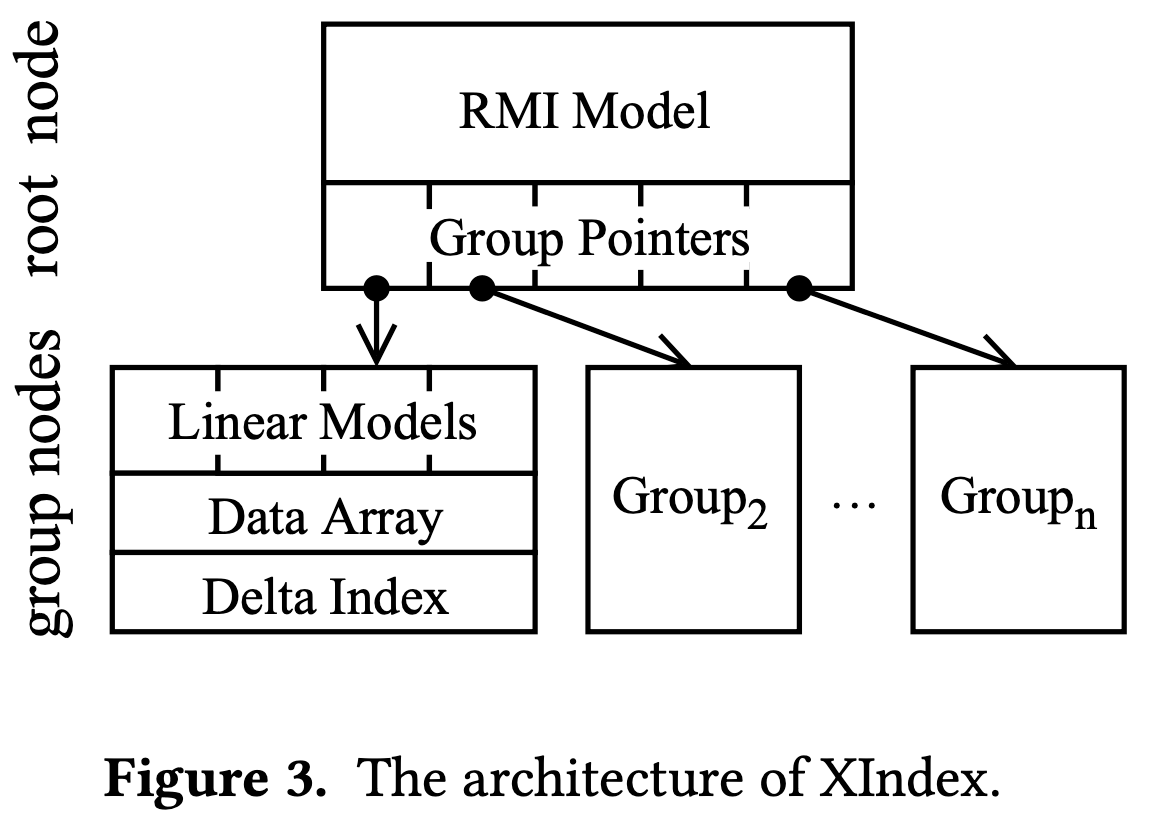
Two-layer Architecture Design
- The root node indexes all group nodes in the bottom layer, by learned RMI model.
- Data is divided into groups by range partitioning
and each group node uses learned linear models to index its data.
write
- Updates in-place
- Associates each group with a delta index to buffer insertions.

buffer_t *buf; // delta index
// buffers all insertions
bool_t buf_frozen; // set to true during compaction
buffer_t *tmp_buf; // temporary delta index
// buffers all insertions during compaction
group_t *next; // used by group split operation
Basic Operations
- Use the root to find the corresponding group.
- Predict a group number with the RMI model.
- Correct the group number with binary search the root.pivots within an error-bounded range.
- Look up the position of the requested record in data_array with the given key.
- Find the correct linear model for the prediction.
(scan group.models → uses the first model whose smallest key is not larger than the target key) - Use the model to predict a position in the group.data_array.
- Correct the position with binary search in a range bounded by the model’s error.
- Find the correct linear model for the prediction.
- …
get
: search buf → search tmp_buf (if it is not null)
put & remove
If a matching record is found,
- Try to update/remove in-place.
- If it is failed, operate on buf or tmp_buf (if frozen_buf flag is true)

scan
: locate the smallest record that is ≥ requested key → reads n consecutive records
- Fine-grained concurrency control
- Readers can always fetch a consistent result
with single read-write lock & version number matching in data_array & delta indexes(buf, temp_buf).

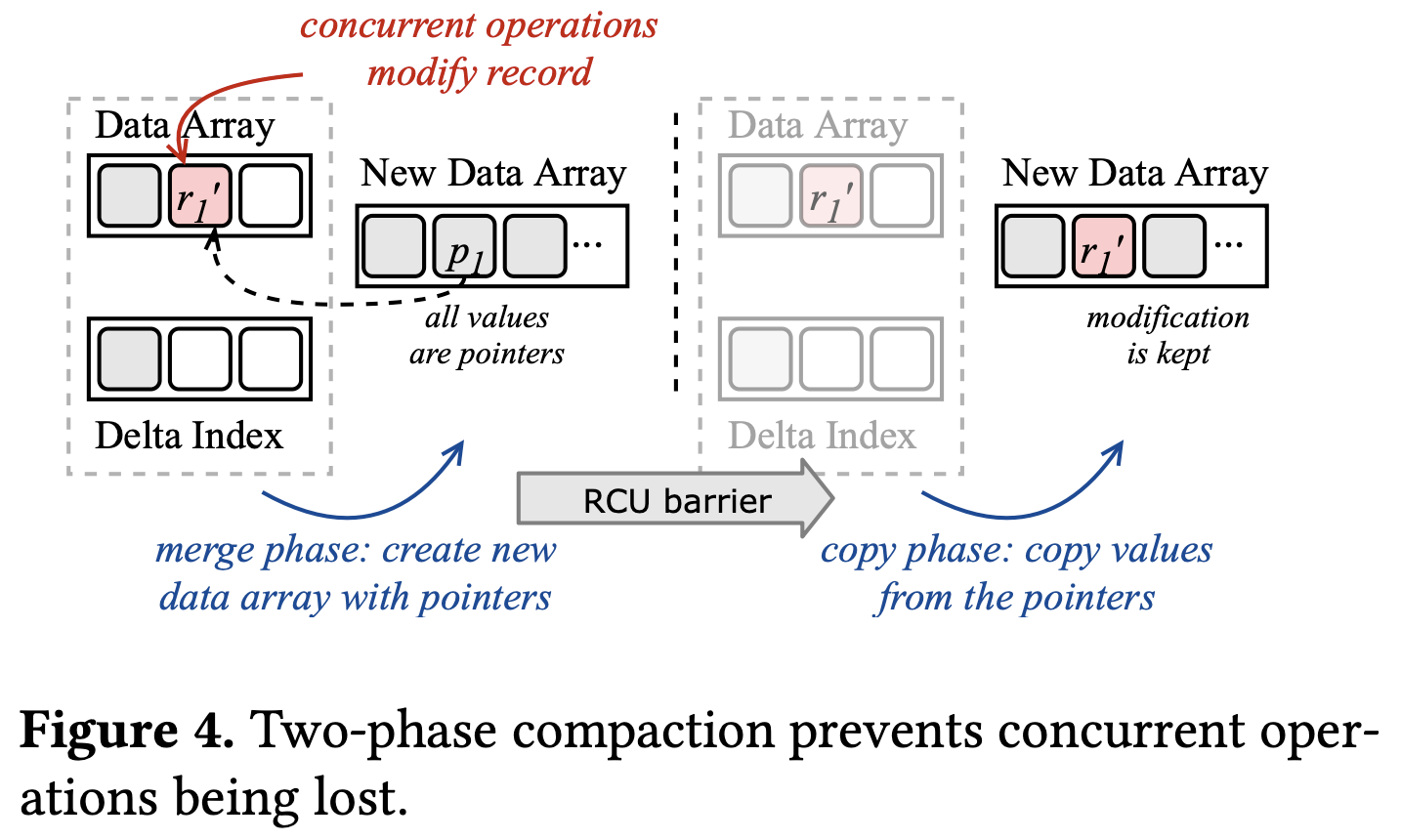
Two-Phase Compaction
- to compact the delta index conditionally
- performed in the background → non-blocking concurrent operations
1. merge phase
: current data array + delta index → new sorted array
(maintain data references, i.e., the values are pointers to existing records)
- During merging, XIndex skips the logically removed records.
2. copy phase
: replaces each reference in the new data array with the latest record value (real data)
- Copy phase is performed when it’s ensured no access on the old data array through an RCU barrier.
- Wait for each worker to process one request, so the old group will not be accessed after the barrier.

Structure Update: Adjusting XIndex at Runtime
XIndex adjusts its structure according to runtime workload characteristics to improve lookup efficiency.
- Basic idea : Keep both error bound and delta index size small with structure update operations.
- Several background threads periodically checks them and performs structure update operations.

- e : error bound threshold
- m : model number threshold
- f ∈ (0, 1) : tolerance factor
- s : delta index size threshold
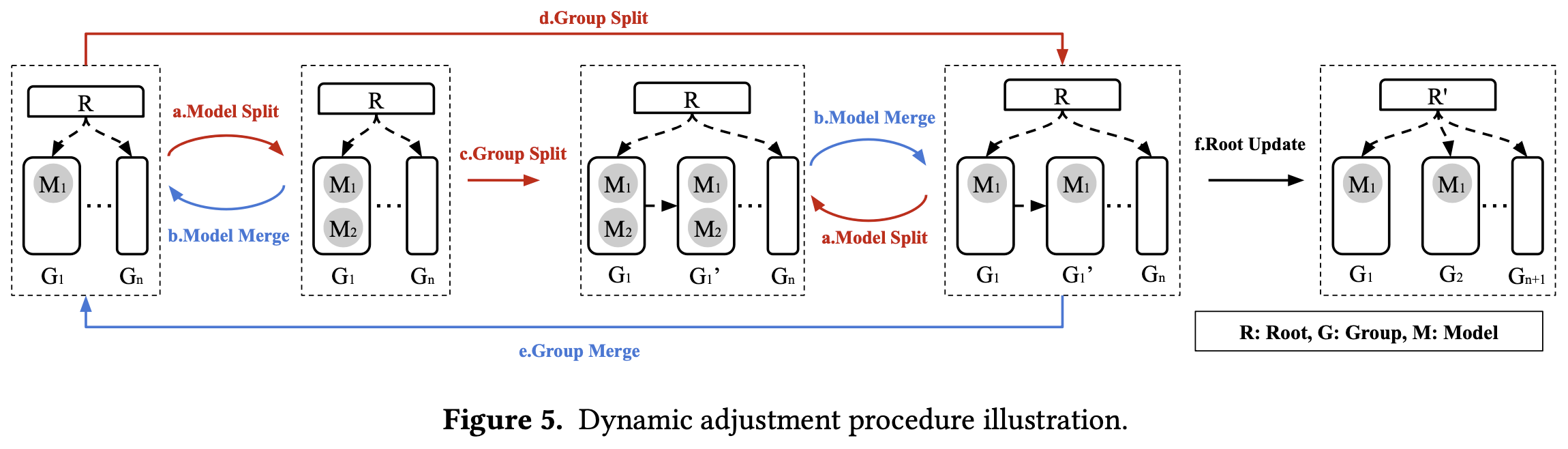
Model split / merge
If some group incurs high prediction error, add more linear models in that group.
Group split
If a group has too many models or its delta index is too large, replace the group with two new groups.
- step 1 : Create two logical groups, sharing data & delta index + temporary delta index for each.
- step 2
- merge phase :
data_array + buf → tmp_array → split it with the key of g’_b.pivot→ initialize two groups (g_a, g_b) - copy phase :
The references in data_array are replaced with real values.
- merge phase :

Group merge
- merge phase
- copy phase
Root update
If there is any group created or removed, root update is performed.
- average error bound > e → increase the number of 2nd stage models of root’s 2-stage RMI)
- average error bound ≤ e × f → reduce models
If there are too many groups,
- flatten root’s groups to reduce pointer access cost (create a new root node with a flattened groups)
- retrain the RMI model
to improve the accuracy.
Evaluation
내일 써야징
'Database' 카테고리의 다른 글
| [Oracle] Database Physical & Logical Storage Structures (4) | 2024.07.02 |
|---|---|
| [Concurrency Control] Optimistic Version Locking (2) | 2024.06.10 |
| Bottom-Up Build of a B+-Tree (Bulk-Loading) (4) | 2024.01.01 |
| Separation or Not: On Handing Out-of-Order Time-Series Data in Leveled LSM-Tree (0) | 2023.09.07 |
| LSM-Tree에 대한 고찰 (4) | 2023.08.17 |


