

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 스케줄링
- concurrency
- 기아 상태
- mutex
- 세마포어
- 페이지 대치
- 페이지 부재율
- PYTHON
- 스레드
- 교착상태
- 페이징
- 단편화
- 트랩
- 백준
- Oracle
- Algorithm
- 부동소수점
- mips
- BOJ
- 운영체제
- 인터럽트
- 가상 메모리
- 동기화
- 프로세스
- 알고리즘
- ALU
- 추상화
- fork()
- 컴퓨터구조
- 우선순위
- Today
- Total
봉황대 in CS
[알고리즘] Disjoint Set & Union-Find 본문
[알고리즘] Disjoint Set & Union-Find
등 긁는 봉황대 2022. 12. 25. 00:38최소 신장 트리(Minimum Spanning Tree, MST)에 대해서 찾아보다가
이를 구현하는 두 가지 방법 중 크루스칼(Kruskal) 알고리즘의 기본 베이스가 Union-Find 임을 보고, 먼저 Union-Find에 대해서 공부한 후 정리해보고자 한다.
Union-Find
Union-Find 알고리즘은
여러 개의 노드가 존재할 때 두 개의 노드를 선택한 후, 현재 이 두 노드가 서로 같은 그래프에 속하는지를 판별하는 알고리즘이다.
Disjoint Set
Disjoint Set(분리 집합)은 공통 원소가 없는, 상호 배타적인 부분 집합들로 나눠진 원소들에 대한 자료구조인데,
이 Disjoint Set을 표현할 때 사용하는 알고리즘이 바로 Union-Find 알고리즘이다.
이 알고리즘은 전체 집합에서 구성 원소들이 겹치지 않도록 분할(Partition)하는 데에 자주 사용된다.
이때 분할이란, 각 부분 집합이 아래의 두 가지 조건을 만족하는 Disjoint Set이 되도록 쪼개는 것을 말한다.
1. 분할된 부분 집합을 합치면 원래의 전체의 집합이 된다.
2. 분할된 부분 집합끼리는 겹치는 원소가 없다.
Union-Find의 연산
연산은 총 3가지이며, 다음과 같다.
1. make-set(x)
초기화
즉, x를 유일한 원소로 가지는 새로운 집합을 생성
2. union(x, y)
x가 속한 집합과 y가 속한 집합을 합침
3. find(x)
x가 어떤 집합에 속해 있는지를 찾아 반환
반환하는 값은 x가 속한 집합의 root 노드 값 (= 대표값)
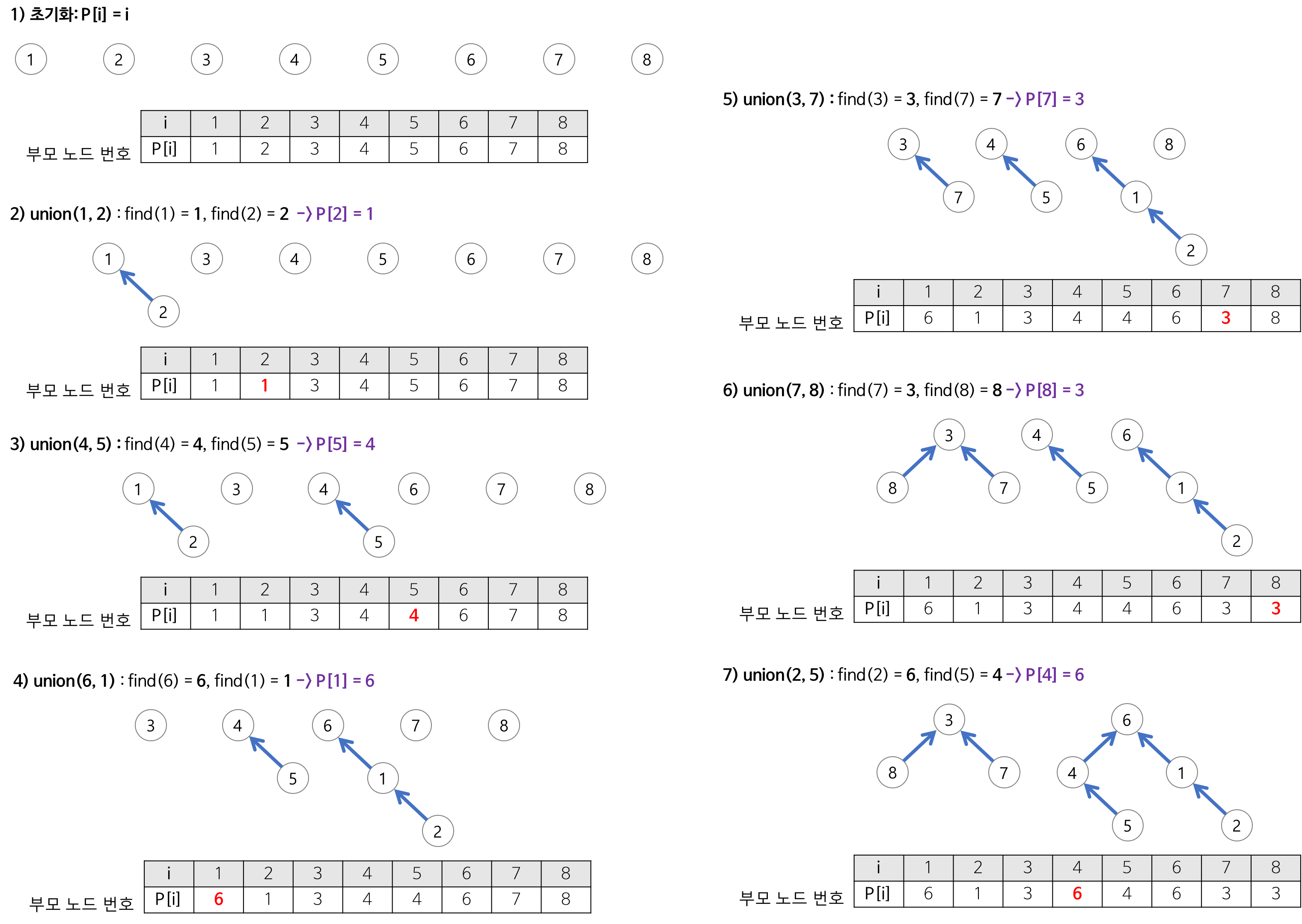
1. 아래처럼 여러 노드가 서로 연결되어 있지 않고, 각자 자기 자신만을 집합의 원소로 가지고 있는 경우를 생각해 보자.
* 각 노드의 색은 그가 속한 집합을 의미

이때 집합을 아래와 같이 표현할 수 있다. (= Disjoint Set)
| 노드 번호 | 1 | 2 | 3 | 4 | 5 |
| 부모 노드의 번호 | 1 | 2 | 3 | 4 | 5 |
모든 값이 자기 자신을 가리키도록 즉, root 노드가 자기 자신이 되도록 초기화하는 것이다. (make-set)
2. 만약 노드 1과 2가 연결되었다고 하면 아래처럼 표현할 수 있다.
부모를 합칠 때는 일반적으로 더 작은 값 쪽으로 합친다. (union)
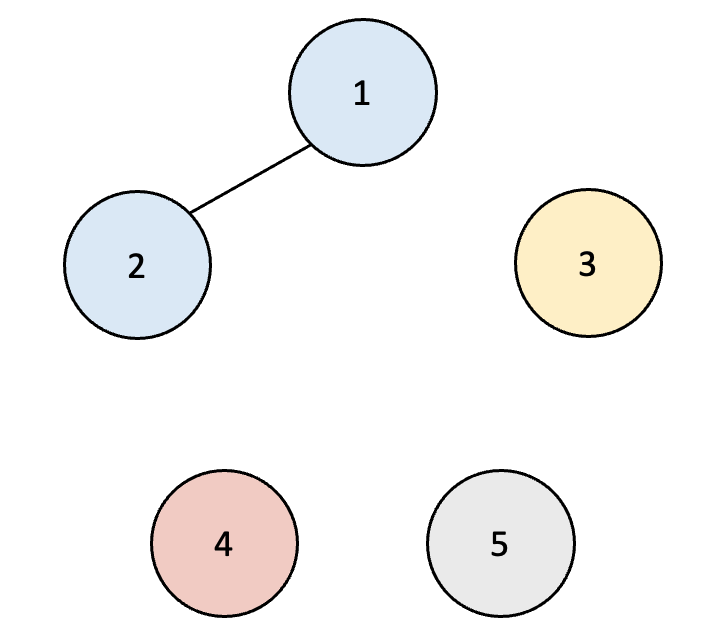
| 노드 번호 | 1 | 2 | 3 | 4 | 5 |
| 부모 노드의 번호 | 1 | 1 | 3 | 4 | 5 |
3. 만약 노드 2와 3이 연결되었다고 하면 아래처럼 표현할 수 있다.
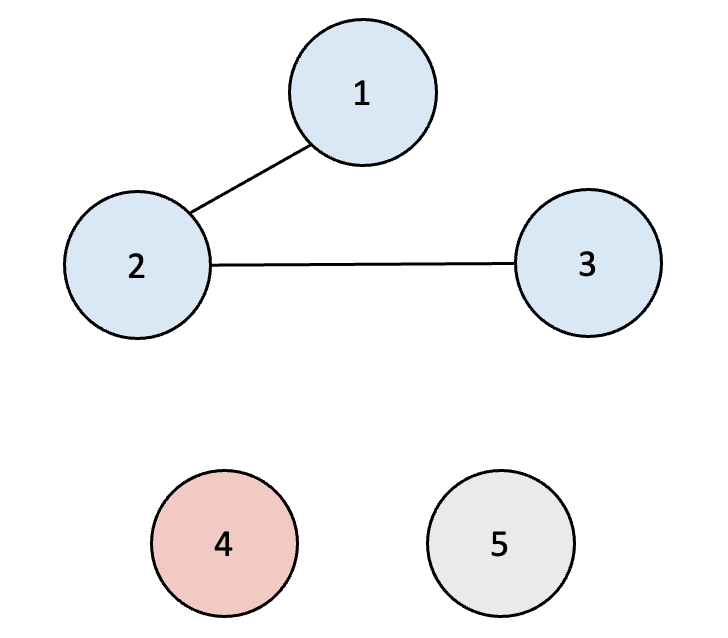
| 노드 번호 | 1 | 2 | 3 | 4 | 5 |
| 부모 노드의 번호 | 1 | 1 | 2 | 4 | 5 |
이렇게 표현한다면 1과 3이 연결되었는지는 어떻게 파악할까?
이때는 재귀 함수를 사용하여 구현하게 된다.
(3의 부모는 2 → 2의 부모는 1 → 1의 부모는 1 → 따라서 3이 속한 집합의 root 노드는 1)
따라서 Union 연산이 전부 수행되고 나면 표는 다음과 같아진다.
| 노드 번호 | 1 | 2 | 3 | 4 | 5 |
| 부모 노드의 번호 | 1 | 1 | 1 | 4 | 5 |
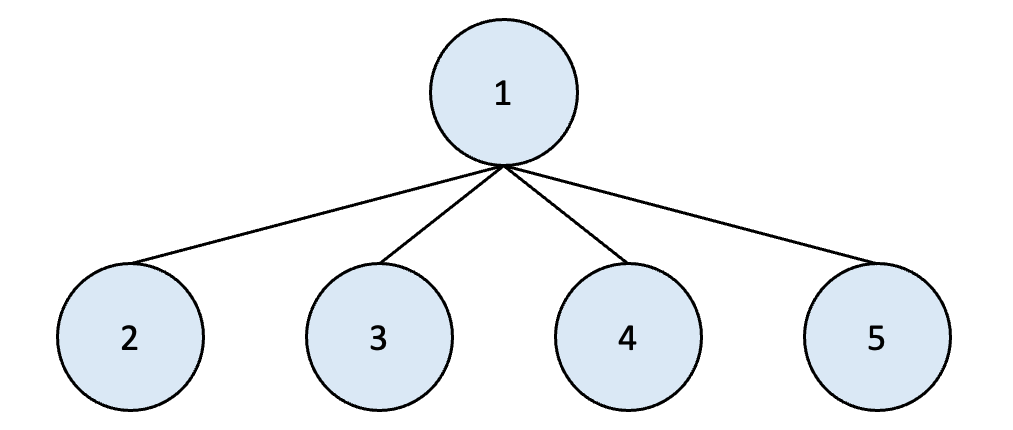
4. find는 두 노드의 root 노드를 확인하는 것을 통해 현재 같은 집합에 속하는지를 확인하는 것이다.
이때도 재귀 함수를 통해 root 노드를 확인하게 된다.
아래의 그림을 찬찬히 본다면 전체적인 그림이 그려질 것이다.
트리 구조의 사용과 그 이유
Union-Find 알고리즘을 구현할 때에는 트리 구조로 구현하게 된다.
집합을 구현하는 데에 여러 자료구조가 사용될 수 있지만, 트리 구조가 가장 효율적이기 때문이다.
트리 구조가 왜 효율적인지는 배열을 사용했을 때와 비교하면서 알아보자.
1. 배열
- Array[i] : i번 원소가 속하는 집합의 번호 (= root 노드의 번호)
- make-set(x) : Array[i] = i와 같이 각자 다른 집합 번호로 초기화
- union(x, y) : 배열의 모든 원소를 순화하면서 y의 집합 번호를 x의 집합 번호로 변경
→ 시간 복잡도 : O(N) - find(x) : 한 번만에 x가 속한 집합 번호를 찾음
→ 시간 복잡도 : O(1)
2. 트리
- 집합 번호 = root 노드의 번호
- make-set(x) : 초기화 시 각 노드는 모두 root 노드임 → N개의 root 노드 생성, 자기 자신으로 초기화
- union(x, y) : x와 y의 root 노드를 찾고, 만약 둘이 다르다면 y를 x의 자손으로 넣어 두 트리를 합침
→ 시간 복잡도 : O(N)보다 작음 - find(x) : root 노드를 통해 같은 집합인지 확인
→ 시간 복잡도 : 트리의 높이와 시간 복잡도가 동일 = 최악의 경우 O(N-1)
구현 (Python)
# make-set, 초기화
root = [i for i in range(N)] # N : 노드의 개수
# find
def find(x):
if root[x] == x: # root 노드의 부모 노드 = 자기 자신
return x
else:
return find(root[x]) # 각 노드의 부모 노드를 찾아 재귀
# union
def union(x, y):
# 1. 각 원소가 속한 트리의 root 노드를 찾음
x = find(x)
y = find(y)
# 2. y의 root 노드를 x의 root 노드로 변경
root[y] = x
find 연산 최적화 - 경로 압축 (Path Compression)
하지만 find 연산을 위처럼 구현한다면 아래와 같이 트리의 높이가 최대가 되는 최악의 상황이 발생할 수 있다.
이는 배열로 집합을 구현한 것보다 비효율적이다.

따라서 find 연산을 다음과 같이 최적화할 수 있다. → 시간 복잡도 : O(logN)
# 최적화된 find, 경로 압축(Path Compression)
def find(x):
if root[x] == x: # root 노드의 부모 노드 = 자기 자신
return x
else:
return root[x] = find(root[x]) # find를 하며 만난 모든 값의 부모 노드를 root로 만듦
즉, find 연산을 하면서 만난 모든 노드들의 부모 노드를 root 노드 번호로 바꾸는 것이다.
union 연산 최적화 - union-by-rank, union-by-height
rank라는 배열에 트리의 높이를 저장한 후, 항상 높이가 낮은 트리를 높은 트리 밑에 넣는 것이다.
root = [i for i in range(N)]
rank = [0 for i in range(N)] # 트리의 높이 저장
# union
def union(x, y):
x = find(x)
y = find(y)
# root가 동일 = 이미 같은 트리
if x == y:
return
# union-by-rank
if rank[x] < rank[y]:
root[x] = y
else:
root[y] = x
if rank[x] == rank[y]:
rank[x] += 1 # 둘의 높이가 같은 경우에는 둘을 합친 후 x의 높이 + 1
문제 추천
1043번: 거짓말
지민이는 파티에 가서 이야기 하는 것을 좋아한다. 파티에 갈 때마다, 지민이는 지민이가 가장 좋아하는 이야기를 한다. 지민이는 그 이야기를 말할 때, 있는 그대로 진실로 말하거나 엄청나게
www.acmicpc.net
'Computer Science & Engineering > Algorithm' 카테고리의 다른 글
| [알고리즘] 분할 정복, Divide-and-Conquer (0) | 2022.12.29 |
|---|---|
| [알고리즘] Minimum Spanning Tree - Kruskal & Prim Algorithm (0) | 2022.12.28 |
| [알고리즘] 배낭 문제, Knapsack Problem (0) | 2022.08.27 |
| [알고리즘] 플로이드-와샬(Floyd-Warshall) 알고리즘 (0) | 2022.07.11 |
| [알고리즘] BFS와 DFS의 개념, 차이점과 구현(Python) (0) | 2022.07.02 |


